While traditional assessments offer snapshots of student knowledge, it often fails to capture the dynamic nature of learning and the intricate interplay of students’ cognitive and metacognitive skills. With this, the burgeoning field of Educational Data Mining (EDM) research provides promise for innovative assessment that can provide deeper insights into student learning and inform effective teaching strategies. However, there are limited EDM research in Philippine educational systems that existing literature reviews on EDM applications often have broader geographical scope and may not capture the unique challenges and opportunities with the Philippine educational systems. This systematic mapping analyzed existing research on EDM applications to predict or improve student performance within Philippine educational contexts. Eighteen (18) EDM research in the Philippines were evaluated. The results showed that current Philippine EDM research focuses to make predictions or classifications of student performance or behavior, such as academic achievement, online learning adaptation, procrastination, and learning styles. Specifically in mathematics education, current EDM research explored broader applications focusing on general academic performance, online learning effectiveness, and student risk factors. A wide range of student data attributes such as age, sex, and parents’ education for demographic data, online learning skills for behavioral data, and overall grades and GPA for performance data are actively utilized in Philippine EDM research. A variety of algorithms lead by traditional algorithms – Naïve Bayes and Decision Trees, have been successfully employed to carry out EDM tasks. The study also identified challenges related to data quality, availability, and ethical considerations. By identifying these trends and applications, this study can inform future efforts to leverage educational data for improving learning outcomes within the Philippine educational system.
Equipping students with the skills they need to succeed in the 21st century is a primary goal for all educational systems worldwide. A strong foundation in many subject areas, especially in mathematics, is key to equipping students with critical thinking, problem-solving skills, and technology-literacy to fostering future success in Science, Technology, Engineering, and Mathematics (STEM) fields. However, ensuring mastery in most subject areas, specifically in Mathematics, remains a global challenge 1, including and especially in the Philippines 2. Despite ongoing educational reforms, the Philippines faces a particular challenge in learning as evidenced on its consistently lower scores on international assessments even compared to other southeast Asian countries 3. This persistent concern necessitates educators to explore innovative approaches to identify at-risk students and personalize learning interventions to improve students’ performance especially in Mathematics.
Traditional methods for identifying academically-struggling students and optimizing learning often rely on limited data points, such as traditional standardized tests. However, this reactive approach may not capture the varying nuances of student learning trajectories 4. Educational Data Mining (EDM) offers a potential solution to address these challenges by leveraging student data to predict performance and tailor interventions 5. EDM analyzes vast amount of educational data, allowing a more comprehensive and dynamic understanding of student performance 6. EDM techniques extract valuable insights from these student data to learning patterns, predict potential difficulties, and personalize learning experiences. By identifying students’ at-risk of falling behind, mathematics educators can proactively implement targeted interventions and optimize learning strategies.
While there has been a growing body of research exploring the applications of Educational Data Mining in various educational contexts, its application in the Philippines remain underexplored. Building upon the broader literature on EDM applications around the world 7, 8, 9, this systematic mapping sheds light on the specific potential of EDM for improving educational outcomes in the Philippines. There is a limited research in Philippine educational systems that existing literature reviews or meta-analyses on EDM applications often have broader geographical scope and may not capture the unique challenges and opportunities with the Philippine educational systems. To date, a comprehensive analysis of how EDM techniques have been utilized to address the challenges of mathematics learning in Philippine schools is lacking.
This systematic mapping aims to address this gap by systematically analyzing existing research on EDM applications within Philippine education. This study will focus on EDM techniques used to predict and improve student performance, and to identify to what extent is Mathematics performance a focus on these existing EDM research. By synthesizing the findings of relevant studies, this study aims to contribute insights on: (1) the effectiveness of different EDM techniques in predicting and enhancing Filipino students’ performance, (2) the commonly used data sources and student characteristics considered within Philippine EDM research, and (3) the potential areas for future research and practical applications of EDM in the Philippines, especially for mathematics education.
To systematically map the trends and applications of Educational Data Mining in the Philippine education in improving student performance, the following research questions were explored:
1. What were the focus of Educational Data Mining research in the Philippines in terms of:
1.1. reported outcomes?
1.2. student data attributes (Demographic, Behavioral, and Performance)?
1.3. mathematics performance?
1.4. grade level?
2. What EDM techniques, computational tools, and algorithms are used in Philippine EDM research?
3. What are the major challenges and limitations faced by Philippine researchers in applying EDM?
This study employed a Systematic Mapping of Literature methodology outlined by 10. This rigorous approach involved several distinct stages. First, clear research questions were formulated to guide the search process. Next, specific inclusion and exclusion criteria were established to ensure the relevance of the identified studies. Following this, a comprehensive search and selection process was undertaken to identify articles that met the established criteria. Once identified, each article was carefully evaluated to assess its quality and suitability for inclusion in the final analysis. Finally, data was extracted from the selected studies. The analysis and presentation stage then commenced, with the extracted data being presented in a clear and informative manner through tables, and descriptive text. This tabular and textual representation of the data facilitated the interpretation of the results and subsequent discussions within the study.
2.1. Search StrategyA multi-pronged search strategy was employed to ensure the retrieval of the most comprehensive dataset possible. This strategy encompassed both automated electronic database searches and a targeted manual search of conference proceedings. The electronic databases utilized included: (1) the Institute of Electrical and Electronics Engineers (IEEE) database, (2) Science Direct by Elsevier, (3) the Association for Computing Machinery (ACM) Digital Library, and (4) Google Scholar.
This selection aimed to capture a broad spectrum of publications within the field of computer science, mathematics, and education. In addition to electronic database searches, the researchers conducted a manual search in Science and Education Publishing (SciEP) to ensure comprehensive coverage of the literature. The inclusion of SciEP was motivated as it contain relevant studies that are not indexed in the major databases typically used for systematic reviews. Especially in niche research areas, manually searching smaller publishers or conference proceedings can help capture important contributions that might otherwise be missed, thereby increasing the chance of potentially shedding light on social and cultural factors specific to the Philippine context of educational data mining and learning analytics.
The search queries employed within the electronic databases leveraged a combination of keywords, synonyms, and related terms to maximize the capture of relevant studies. The specific search string utilized in English was formulated as: (‘EDM’ OR ‘education data mining’ OR ‘educational data mining’) AND (‘Philippines’ OR ‘Filipino students’) OR (‘mathematics learning’ OR ‘mathematics’). This comprehensive search strategy ensured a thorough exploration of the literature on the intersection of educational data mining, student performance, and in the context of the Philippines.
2.2. Result FiltersThe articles were selected according to the following Inclusion and Exclusion Criteria: Inclusion Criteria includes (1) studies focusing on student performance, (2) studies that used EDM or LA techniques, (3) studies that addressed courses at the secondary, undergraduate or graduate levels, (4) studies that addressed the use of tools to apply EDM and LA techniques, (5) studies in the context of Philippine Education, (6) studies written in English or Filiipino, and (7) studies published between January 2015 and March 2024. On the other hand, exclusion criteria includeds (1) studies whose focus is not on student performance, (2) studies that did not deal with EDM, (3) Conference papers, review papers, books, magazines, editorials, notes, and short survey, and (4) Duplicate reports of the same database.
This study employed a four-stage article selection process as can be seen in Figure 1. In the first stage, a comprehensive search strategy was implemented, utilizing both automated and manual techniques across relevant databases and conference proceedings. Duplicate entries were eliminated, yielding a preliminary pool of 451 articles. Stage two involved a title, abstract, and keyword screening to identify potentially relevant studies. This process resulted in the exclusion of 322 articles, leaving 129 articles for further evaluation. In stage three, a more rigorous selection process was applied. The introductions, results, and conclusions of the remaining articles were critically reviewed to ensure alignment with the pre-defined inclusion and exclusion criteria. If the aforementioned sections provided insufficient information for a definitive decision, a full-text review was conducted. This stage led to the exclusion of 94 articles, resulting in a selection of 35 articles for the next phase. Finally, stage four involved a critical appraisal of the remaining 18 articles, with data extraction procedures implemented to gather relevant information for analysis.
During the fourth screening stage, the thirty-five (35) remaining studies underwent full-text assessment. Articles were excluded if the full text was unavailable, if they lacked empirical results, or if they were not directly aligned with educational data mining in mathematics learning. Applying these criteria reduced the set to eighteen (18) studies for final evaluation. The table below shows the articles obtained.
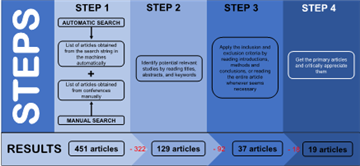
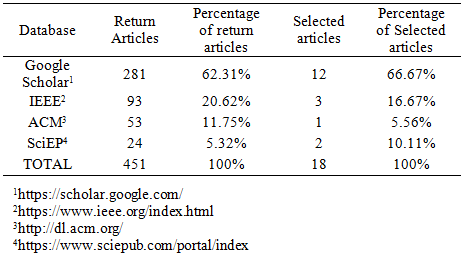
Table 1 presents the articles obtained after the 4-stage selection process. The 18 selected primary articles are largely from Google Scholar, with 66.67%. Three articles are retrieved from IEEE Database while two studies and one study are retrieved from Science and Education Publishing (ScieEP) and the Association for Computing Machinery (ACM) Digital Library, respectively.
To provide a better mapping of EDM research done in the Philippines, Table 2 presents the distribution of the 18 primary research articles on Educational Data Mining (EDM) as applied to student learning in the Philippines, categorized by geographic area. As evident from the table, Luzon boasts the highest number of studies (n=7) investigating EDM in this context. This includes studies of 11, 12, 13, 14, 15, 16, 17. This aligns with the findings of 18who highlight the concentration of research resources in Luzon, the most populous region in the Philippines. Mindanao follows closely with seven studies (n=7) exploring EDM for student learning as studied in the researches of 19, 20, 21, 22, 23. This suggests a growing interest in utilizing EDM to improve educational outcomes in the southern regions. The Visayas region has a slightly lower number of studies (n=2) applying EDM to student learning 24, 25. Further research efforts may be needed to bridge this gap and ensure a more geographically balanced application of EDM in Philippine education. Two studies (n=2) did not specify the geographic area of their research of 18, 26.
RQ1: What were the focus of Educational Data Mining research in the Philippines in terms of:
1.1. reported outcomes?
11 employed a data-driven approach to investigate various aspects of student academic performance. The research aimed to identify average grade levels disaggregated by gender, determine the higher-performing gender group, pinpoint subjects with the strongest and weakest student performance, and explore academic achievement based on prior school and parental occupation. Additionally, the study sought to develop a predictive model to inform marketing strategies for schools with low enrollment. While a Naive Bayes classifier achieved a high accuracy (92.37%) for the academic performance model, the model designed for predicting enrollment yielded a lower accuracy (30.97%). These findings suggest that the chosen machine learning technique was effective in modeling student achievement but less successful in predicting enrollment patterns.
18 investigated the potential of education data mining techniques to identify student performance and unexpected benefits in a distance learning environment. Their goal was to leverage this information to propose practical solutions for mitigating future crises in higher education. The study employed decision tree analysis, specifically the C4.5 algorithm, to assess student adaptation to online learning. Data was collected through a Google form survey administered to 150 students. The authors acknowledged the inherent challenges of transitioning practical agricultural courses to a fully online format. They posited that the insights gleaned from this study could inform curriculum development for a new educational standard within the agricultural education system.
27 investigated the online learning experience through analysis of student access patterns. The findings suggest that increased opportunities for collaborative activities, such as discussion forums, can positively impact student engagement. Notably, a significant portion of student access to the course site involved discussion forums, including both viewing and posting. Additionally, the introduction forum emerged as a key resource for students to learn from their peers. The study further highlights the utility of data mining techniques, particularly statistics, clustering approaches, and visualization, in analyzing online learner access patterns, behaviors, and ultimately, their academic performance.
19 revealed a pattern of disparity in their investigation of student performance in mathematics-related courses. Students exhibited strong performance in the "Modern World Mathematics" course, evidenced by a mean rating of 2.16 (SD=0.27). Conversely, performance in "Mathematics Enhancement 1" and the programming course proved to be significantly lower, with mean grades of 2.81 (SD=0.38) and 2.64 (SD=0.39), respectively. Intriguingly, a positive correlation emerged between performance in mathematics and programming, suggesting a potential influence of mathematical competency on programming proficiency. Furthermore, the study identified a gender disparity, with female students outperforming males in the programming course.
12 employed the RapidMiner tool to evaluate various clustering algorithms for student grouping. The analysis included Density-Based Spatial Clustering of Applications with Noise (DBSCAN), k-means, k-medoids, expectation maximization clustering, and support vector clustering. Silhouette analysis was used to assess the performance of each algorithm, and k-means with k=3 emerged as the most suitable approach, yielding a silhouette index of 0.196. This resulted in the classification of students into three distinct clusters: a large group of 477 (cluster 0), a proficient group of 310 (cluster 1), and a developing group of 396 students (cluster 2).
20 developed a decision-tree model to identify students at risk of dropping out of school. The model incorporates three key factors: prior grade retention, family size (number of siblings exceeding six), and academic performance (average grades categorized as "fairly satisfactory" or "satisfactory"). Students with a history of retention were identified as most at risk. Those without retention but with large families (more than six siblings) were also flagged for potential dropout. Finally, the model indicated that students with neither retention nor a large family size, but whose academic performance fell within the "fairly satisfactory" or "satisfactory" range, were still susceptible to dropping out. This intelligent model offers educational institutions and stakeholders a proactive approach to identify and address student dropout risk, ultimately aiming to reduce dropout rates.
21 investigated the use of data mining techniques to predict student success in higher education. The authors implemented various algorithms, including k-Nearest Neighbors (kNN), Classification and Regression Trees (CART), Adaptive Boosting, and Logistic Regression. Their analysis revealed that Adaptive Boosting achieved the highest accuracy (92.20%), followed by Logistic Regression (92.09%), CART (89.70%), and kNN (80.50%). The models were trained on a dataset collected from Mindanao State University – Marawi during the 2010-2015 academic years. To ensure model robustness, the research employed 10-fold cross-validation, a technique that strengthens the generalizability of the findings. This approach aimed to identify the most effective data mining model for predicting student outcomes in higher education institutions, with the goal of classifying students as "AtRisk" or "NotAtRisk".
14 compared the effectiveness of two data mining algorithms, C4.5 and CHAID, in predicting student academic performance. While both algorithms achieved statistically significant accuracy, CHAID exhibited a slight edge. However, the researchers favored CHAID as the optimal early warning system due to unspecified evaluation criteria. This suggests that CHAID may have offered advantages beyond pure classification accuracy, potentially related to model interpretability or efficiency. The study concludes that CHAID is a suitable modeling approach for identifying students at risk of academic failure within a specific program.
25 propose a novel data-driven approach for analyzing student learning behavior in Moodle courses. This method involves analyzing student action logs to generate visualizations that instructors can use to monitor student activity throughout the course. The study employed log data from blended courses offered at a university using Moodle. Initial findings suggest the approach has promise in revealing variations in student behavior, including patterns of resource access, engagement with assessment tasks, and overall course interaction. The authors conclude by highlighting areas for further development and outlining plans for future research.
17 investigated factors influencing program completion in higher education. The study identified parents' monthly income, mother's and father's educational attainment, and high school GPA as the most significant predictors of program completion. Using a 70/30 training/testing split, a data mining model achieved an accuracy of 84% in predicting program completion, with precision and recall exceeding 80% for both graduating and non-graduating students. These findings suggest that the developed model can be a valuable tool for higher education institutions (HEIs) to identify students at risk of non-completion, allowing for targeted interventions to improve graduation rates.
28 explored faculty perceptions of writing assistance tools in the context of research writing. While faculty valued these tools for their ability to expedite research writing and enhance clarity, the study identified potential drawbacks. These included overreliance on the tools, hindering the development of critical thinking and writing skills. Additionally, concerns were raised regarding potential for plagiarism with irresponsible use, along with technological and resource challenges. The authors emphasize the importance of considering cultural and language specificities, as these tools might not be optimized for Filipino academic writing's nuances. Overall, the study offers valuable insights for researchers, educators, and software developers seeking to utilize AI for streamlining research writing processes within the educational sector.
26 employed data mining techniques to develop a decision tree model for learning style classification. Utilizing the J48 algorithm on data from 408 out of 462 information technology students at a Philippine state university, the study yielded four distinct decision trees with conditional rule models corresponding to activist, reflector, theorist, and pragmatist learning styles. The accuracy of these models, evaluated through confusion matrix and receiver operating curve analysis, demonstrated a very high success rate in learner style detection (weighted average of 88-96%). This suggests the potential application of this approach in a practical learning environment, enabling efficient and accurate learning style identification based on student characteristics.
22 employed a Multi-Layer Perceptron (MLP) neural network model to investigate factors influencing online academic performance. The formulated model achieved a high testing accuracy of 0.932, indicating strong performance in predicting outcomes. Further evaluation using Cohen's kappa coefficient (0.891) and F-measure (0.924) supported the model's reliability. This accurate model facilitated a sensitivity analysis via Partial Dependence Measures (PDM) to identify the most influential factors. The analysis revealed that motivation and mental well-being emerged as the most critical factors impacting both below average and above average online academic performance.
15 examined the academic performance of BSIT students, revealing that both lecture and laboratory grades hover around the average level. While students demonstrated a preference for Multimedia and Network Management courses, software development remained a significant area of weakness. The analysis also indicated a projected increase in student grades, though these improvements are expected to remain within the average range. These findings suggest a need to strengthen the delivery of BSIT core concepts, theories, and their practical application. Faculty development programs focused on software development pedagogy are recommended. Additionally, incorporating real-world software development experiences through industry partnerships or in-house initiatives could benefit both faculty and students.
16 employed a descriptive-survey design to explore student experiences with a learning management system (LMS) using a modified Technology Acceptance Model (TAM) questionnaire. The questionnaire assessed four key dimensions: perceived usefulness (PU), perceived ease of use (PEOU), behavioral intentions (BI), and actual use (AU). Quantitative data from the survey revealed positive student experiences, with "strongly agree" ratings for PU, PEOU, and BI. Actual use received an "agree" rating, suggesting a slight decrease in positivity. Qualitative data, gathered through an open-ended question, was analyzed using sentiment analysis techniques within an open-source machine learning and data mining toolkit. This analysis revealed a "neutral" sentiment overall. The authors recommend further investigation for researchers pursuing advanced studies in this area.
13 investigated the efficacy of deep learning for predicting student academic performance. Their findings revealed that the deep learning classifier achieved a superior overall forecast accuracy of 95% compared to other classification methods employed in the study. These results suggest the potential of deep learning to significantly impact student success. Furthermore, the authors identify several promising avenues for future research. The ability to predict student performance offers valuable insights for college administrators and faculty members, enabling them to implement targeted interventions and optimize educational practices.
24 explored the use of a machine learning approach to predict students' procrastination tendencies in online mathematics learning. Their investigation identified 14 relevant features from an initial set of 35. Utilizing a Gaussian-Bernoulli Mixed Naïve Bayes model, the authors achieved an impressive prediction accuracy of 89% and a Kappa score of 84% in classifying students into four categories: Non-Procrastinators, Low, Moderate, and High Procrastinators. This indicates the model's strong potential for educators to proactively identify students at risk of procrastination and implement targeted interventions to mitigate its negative impact on learning outcomes in online mathematics courses.
23 investigated the potential for predicting student procrastination tendencies. Their study employed a Gaussian-Bernoulli Mixed Naïve Bayes model to analyze student data and identify relevant features. The results revealed five key features that significantly contributed to predicting procrastination behavior. Furthermore, the model achieved a high level of accuracy (85% testing accuracy) and reliability (82% Kappa score) in predicting students' likelihood of procrastinating. This suggests that the model can be a valuable tool for mathematics educators and administrators to proactively identify students at risk of procrastination and implement preventative measures to mitigate its negative academic consequences.
1.2 Mathematics performance
Of the 18 research studies that explored the application of Educational Data Mining in improving student learning, only three are specific to students’ Mathematics performance. The majority of these studies explored broader applications of EDM in Philippine education, focusing on general academic performance, online learning effectiveness, student risk factors, and learning styles. However, the existence of studies on Math performance, even if limited, demonstrate the potential for EDM to be used more extensively explored in this domain. This could lead to further research and development of EDM tools specifically for improving Mathematics learning outcomes.
1.3 Student Data Attributes
EDM studies use different student attributes to make predictions, clusters, or any mining methods as their data. These data are usually contained on a school’s data repository or database system. To categorize these various students data used in EDM studies, the study follows the categorization of data characteristics from 8.
In this study, student data used for EDM researches in the Philippines are categorized into three: (1) Demographic, (2) Behavioral, and (3) Performance. Within the context of educational platforms, demographic data encompasses user attributes that define the learner population. This data is typically collected through administrative records, either before or after enrollment in offered courses. In contrast, behavioral data pertains to the methods users employ to access the platform and interact with its functionalities. Furthermore, performance data refers to the utilization of student grades or any other form of assessment information.
For Demographic attributes, there is a focus on demographic characteristics, with student sex/gender being the most frequently explored feature (n=9). Demographics dominate the feature set, with researchers like 26 and 24 utilizing features like age and sex/gender to understand student profiles. This aligns with the need for contextual information to enhance the effectiveness of EDM models. Educational Background features are also prevalent (n=3-4), with studies by 13 and 24 incorporating data on student courses and year levels. This allows for tailoring educational interventions to specific student groups. Location features appear frequently (n=5), with both general information like address, like in the study of 20 and specific details like campus in the study of 18 being used. Understanding student location can be valuable for personalized learning initiatives. Other Features encompass a diverse range of characteristics used in specific studies (n=1 each). These include details like student code in 13, family background such as parents' education in 20, and even health data such as blood type in 21. The inclusion of such features highlights the potential for rich student profiles in EDM research. Interestingly, some features appear limited in their use. For example, features like "last school attended" or "parents' occupation" used also by 11 might benefit from further exploration to understand their potential impact on student learning outcomes.
Overall, Philippine EDM research demonstrates a reliance on demographic and educational background data to understand student profiles and tailor interventions. While location data is also considered valuable for personalization, there's potential for richer student profiles by incorporating a wider range of features, but some less-used features might require further investigation.
For Behavioral attributes, a concentration on learning skills and attitudes, particularly those relevant to online learning environments.
Learning Skills & Attitudes dominate the attribute set, with features like "Overall Attitudes Towards Online Learning" and "Time Management" appearing in multiple studies, such as in the studies of 24 and 22. This aligns with the growing emphasis on understanding student online learning readiness for effective online education delivery 29.Interestingly, literature also showed a focus on specific aspects of online learning. Studies by 23 and 22 explored "Online Learning Readiness," highlighting the importance of preparing students for online learning environments. Similarly, features like "Time Management" (used by multiple studies) emphasized skills crucial for success in online learning contexts. While Learning Challenges receive less attention, features like "Mathematics Anxiety" used by 23 and 24 highlight potential areas of difficulty that EDM research can address. The "Other" category encompasses a broader range of attributes used in specific studies (n=1 each). This category demonstrates the potential for exploring various student characteristics beyond traditional academic performance metrics. For instance, 22 examine "Mental Well-being" and "Socioeconomic Status," indicating a shift towards a more holistic understanding of student learning.
It's noteworthy that some attributes appear in single studies. For example, "Motivation for Learning" used by 18 is a well-established factor in educational research, and its potential for integration with EDM techniques warrants further exploration.
Overall, the use of behavioral attributes reflects a growing focus on student attributes beyond academic performance in Philippine EDM research. The emphasis on online learning skills and attitudes aligns with the rise of online education. Additionally, the inclusion of diverse attributes in the "Other" category highlights a trend towards a more comprehensive understanding of the student experience. Future research might benefit from investigating the effectiveness of specific attribute combinations for improving student learning outcomes.
And for Performance attributes, Academic Performance (Overall) dominates the attribute set, with features like "Grades" (used by multiple studies) being a mainstay in educational assessment, e.g., 11 and 14. Similarly, GPA (Grade Point Average) is a widely used metric for overall academic achievement, appearing in studies by 21 and 13. This aligns with the established role of academic performance data in educational research 30. Literature also highlights the use of Academic Performance (Specific) attributes. Entrance exam scores used by 21 and grades in specific subjects like Math grades 23 provide more granular insights into student performance. The "Other" category encompasses a diverse range of attributes used in specific studies (n=1 each). This category showcases the potential for exploring alternative performance indicators beyond grades. For instance, 20 examines "Dropout" rates, highlighting an EDM application for student retention. Additionally, 12 utilizes a comprehensive set of aptitude scores, indicating the potential for exploring student potential in specific academic domains.
It's worth noting that some attributes appear in single studies. For example, "Remarks (Pass or Fail)" used by 13 offers a binary performance indicator, while "Experience Retention" used by 20 is a concept that could be further explored in EDM research.
Overall, performance attributes reflect a reliance on traditional academic performance metrics in Philippine EDM research. However, the inclusion of specific course grades and alternative performance indicators like dropout rates demonstrates a move towards a more comprehensive understanding of student achievement.
1.4 grade level
A significant number of studies are conducted in the higher education level, with 12 studies, and only around half of it are the number of studies conducted in the basic education level (n=6). A number of these studies in the higher education are also conducted to IT students, which means more EDM research are conducted due there due to their more adept in the technical aspect of conducting EDM studies.
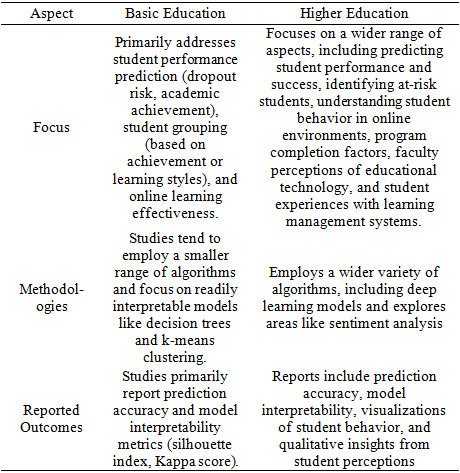
These studies are then analyzed to provide below a table breaking down the focus, methodologies, and reported outcomes of EDM studies in the Philippines, comparing basic education (K-12) and higher education contexts.
An examination of Educational Data Mining (EDM) studies in the Philippines revealed distinct characteristics between basic (K-12) and higher education contexts. Basic education research focuses primarily on student performance prediction, with studies aiming to identify students at risk of dropping out 20 or underperforming in specific subjects 23, 24. Additionally, efforts are directed towards student grouping based on achievement 12 or learning styles 26 to personalize instruction. Machine learning algorithms like decision trees and k-means clustering are frequently employed due to their interpretability and effectiveness in these tasks 12, 20, 26. The reported outcomes in basic education research typically emphasize prediction accuracy and model interpretability metrics (e.g., silhouette index, Kappa score) to ensure the practical application of the findings ( 20, 23, 24
In contrast, higher education EDM research exhibits a broader scope. While studies still address student performance prediction and identifying at-risk students ( 14, 17, 21), they delve into additional areas like understanding student behavior in online environments 25, program completion factors 17, faculty perceptions of educational technology 28, and student experiences with learning management systems 16. This wider range of inquiry reflects the more complex learning ecosystem in higher education. Furthermore, higher education research often utilizes a wider variety of algorithms, including deep learning models 13, and incorporates qualitative analysis methods like sentiment analysis 16 to gain richer insights. Reported outcomes in higher education research encompass prediction accuracy, model interpretability, visualizations of student behavior patterns, and qualitative findings from student perspectives (e.g., 28. This suggests a potential link between the availability of richer datasets in higher education institutions and the exploration of more complex research questions and methodologies.
Overall, the focus on immediate, actionable interventions for student success appears more pronounced in basic education research, while higher education research delves into a broader range of educational issues and student experiences.
RQ2: What EDM techniques, computational tools, and algorithms are used in Philippine EDM research?
Philippine EDM researches reveal a focus on classification and prediction techniques, with both categories having the highest number of studies (n=11). Classification is the dominant technique, as evidenced by studies like 11 and 20 which utilize classification algorithms to categorize students based on their learning styles or at-risk behaviors.
Prediction is another prevalent method, employed in research like 14 and 26 to forecast student performance or learning outcomes. Clustering techniques, used in studies like 24 and 28, appear less frequently (n=5) but are valuable for grouping students with similar learning patterns. This allows educators to tailor instruction to specific student clusters. Visualization techniques, showcased in studies by 27 and 25 (n=2), are used to represent complex educational data in a user-friendly format. This facilitates the identification of patterns and trends in student learning. Natural Language Processing (NLP) techniques, employed in research by 16 and 28 (n=2), are an emerging area in Philippine EDM research. NLP allows for analyzing student text data, such as discussion forum posts, to gain insights into their learning processes.
Overall, there is a diverse application of data mining techniques in Philippine EDM research, with a focus on classification and prediction, it only highlights the goal of using EDM for actionable interventions and improving student performance. While clustering and visualization techniques are present providing valuable insights for differentiated instruction, NLP represents a growing area with promising potential to unlock new understanding from student text data.
About data mining tools employed in EDM research in the Philippines, literature reveals a preference for open-source software with RStudio and RapidMiner emerging as the most frequently used tools (n=4 each).
RStudio is a popular choice for its user-friendly interface and extensive capabilities for statistical analysis, data visualization, and machine learning. Studies like 20 and 22 showcase its application in EDM tasks. RapidMiner is another prominent tool, favored for its visual drag-and-drop interface and pre-built modules for data mining tasks. Research by 11 and 13 exemplifies its use in EDM projects. SPSS (Statistical Package for the Social Sciences) appears as a relevant tool (n=3) in studies like 14 that likely leverage its robust statistical analysis capabilities. Weka (Waikato Environment for Knowledge Analysis) is another open-source option used in a few studies (n=3). Research by 26 exemplifies its application in data mining tasks. R Software is mentioned once (n=1) in the context of 28. This suggests a potential broader use of R beyond RStudio, highlighting its versatility for data analysis.
Overall, the focus on open-source tools like RStudio, RapidMiner, Weka, and potentially R software highlights the resourcefulness of Philippine EDM researchers.The variety of tools used suggests that researchers choose the most appropriate tool for their specific data mining tasks and analytical needs.
On the use of data mining algorithms employed in educational data mining (EDM) research focused on student learning in the Philippines. Literature reveals a preference for a few core algorithms, with Naive Bayes and Decision Tree emerging as the most frequently used (n=6 and n=7, respectively).
Naive Bayes is a popular choice for its simplicity and efficiency in classification tasks. Studies like 11, 24, and 23 utilized Naive Bayes to categorize students based on learning styles or at-risk behaviors. Decision Trees offer interpretability and handle various data types, making them valuable for classification and prediction tasks. Research by 20 and 14 exemplifies their application in EDM projects. Decision Trees are well-suited for educational research due to their ability to identify factors influencing student outcomes 31. K-means clustering, used in studies like 27 and 23, is a common technique for grouping data points into distinct clusters. This allows educators to identify student groups with similar learning patterns.
While the results highlight the prevalence of these core algorithms, it also showcases a diversity of other algorithms used in specific studies (n=1 each). This includes clustering algorithms like DBSCAN, K-medoids, and Expectation Maximization (EM) employed in 12 for tasks potentially involving complex data structures. Additionally, other classification algorithms like K-Nearest Neighbors, Logistic Regression, and Support Vector Machines are used in studies by 21 and 14 for specific classification purposes.
Furthermore, the the emergence of techniques beyond traditional algorithms. 22 utilizes a Multi-Layer Perceptron Neural Network (MLP NN), showcasing the potential of deep learning in Philippine EDM research. Similarly, 16 employs Lexicon-based Sentiment Analysis, and 25 uses the Vector Space Model, indicating an exploration of Natural Language Processing (NLP) techniques for analyzing student text data.
Overall, a focus on core algorithms like Naive Bayes and Decision Trees for classification and prediction tasks. However, it also highlights a growing diversity in algorithm selection, with researchers venturing into clustering techniques, deep learning approaches, and NLP methods to address the complexities of educational data.
RQ3. What are the major challenges and limitations faced by Philippine researchers in applying EDM.
Basing on the reviewed studies, Educational Data Mining (EDM) research for improving student learning in the Philippines holds immense potential for actually augmenting student success and educational practices. However, several challenges and limitations hinder the EDM’s full potential, as evidenced by the reviewed studies.
A significant challenge lies in data quality and availability. Studies often rely on datasets with limited features, potentially hindering the ability to capture the many variations of student learning 11, 20. Furthermore, data specific to student behaviors and learning styles appears scarce in the reviewed literature. While 27 demonstrates the potential of analyzing student online access patterns, this suggests such data collection practices might not be widespread across institutions in the Philippines.
Another concern is the emphasis on achieving high prediction accuracy at the expense of interpretability. Many studies report impressive accuracy rates (such as the studies of 13, 17, 22) but lack detailed explanations of the chosen algorithms or how the results translate into actionable insights. This focus on prediction might come at the cost of understanding the underlying factors influencing student success.
Limited exploration of the complex relationships between various student attributes and learning outcomes is another limitation. Many studies focus on isolated aspects of student performance or behavior, such as the studies of 11, and 19. A more holistic approach that considers the interplay of socio-economic background, learning environment, psychological factors, and academic performance could yield richer insights.
Methodological considerations also warrant attention. Some studies employ less sophisticated data mining techniques like decision trees and k-means clustering, such as in the studies of 20, 12. While effective for specific tasks, these methods might not capture the complexities of student learning processes. The potential of more advanced techniques like deep learning, like used by 13, and 22 is promising, but necessitates addressing the challenges of interpretability and potential biases within these models.
Generalizability of findings also presents a challenge for Philippine EDM studies. Studies often focus on specific contexts, such as only to the students of BS Information Technology students, with limited sample sizes. This raises questions about the extent to which the findings can be applied to the broader Philippine educational landscape. Bridging the gap between research and implementation is another area for improvement. While some studies propose interventions based on their findings (e.g., 20, 24, 23), there is limited evidence of how these interventions integrate seamlessly into existing educational practices. Further research efforts should explore strategies for effective knowledge translation and evidence-based practice in Philippine educational settings from Educational Data Mining studies.
This work presented a Systematic Mapping of literature about the trends and applications of Educational Data Mining methods in addressing pedagogical problems and improving student learning especially in the context of Philippine Education. The systematic mapping of 18 articles demonstrated the growing interest in the burgeoning field of Educational Data Mining research in the Philippines. Researchers are actively exploring its potential to improve student outcomes by investigating various aspects of learning and performance. The studies demonstrated the efficacy of EDM techniques in achieving high accuracy rates for tasks such as predicting student performance, clustering students according to groups, identifying students at risk of dropping out, and understanding learning styles. Of the 18 studies reviewed, use of EDM specific to Mathematics Education is a new idea as it was explored only by three studies. The mining and learning analysis was widely used, which identified five EDM methods with emphasis on classification and prediction, five existing tools led by RStudio and RapidMiner, 18 different algorithms used trailblazed by Naïve Bayes and Decision Trees, and half of the reviewed studies are focused in higher education. Many studies focused on specific aspects of student performance or behavior, such as academic achievement, online learning adaptation, procrastination, and learning styles. This approach provides valuable insights into these targeted areas. However, several studies acknowledged limitations such as data quality and availability, a focus on accuracy over interpretability, and limited generalizability due to small sample sizes or specific contexts. Ethical considerations around student data privacy and potential biases within algorithms require further exploration, and there seems to be a gap between research and implementation as limited evidence of how interventions based on findings integrate into existing teaching practices.
| [1] | J. Jerrim et al., “E ducation E ndowment Foundation Mathematics Mastery Secondary Evaluation Report Independent evaluators,” 2015. [Online]. Available: www. educationendowmentfoundation.org.uk | ||
| In article | |||
| [2] | H. Aguhayon, R. Tingson, and J. Pentang, “Addressing Students Learning Gaps in Mathematics through Differentiated Instruction,” International Journal of Educational Management and Development Studies, vol. 4, no. 1, pp. 69–87, Mar. 2023. | ||
| In article | View Article | ||
| [3] | “PISA 2022 Results Factsheets Philippines PUBE,” 2023. [Online]. Available: https://oecdch.art/a40de1dbaf/C266. | ||
| In article | |||
| [4] | J. Sarama et al., “Testing a Theoretical Assumption of a Learning-Trajectories Approach in Teaching Length Measurement to Kindergartners,” AERA Open, vol. 7, 2021. | ||
| In article | View Article | ||
| [5] | S., & I. P. S. Baker, Emergence and Innovation in Digital Learning: Foundations and Applications. Athabasca University Press, 2016. | ||
| In article | |||
| [6] | M. Yağcı, “Educational data mining: prediction of students’ academic performance using machine learning algorithms,” Smart Learning Environments, vol. 9, no. 1, Dec. 2022. | ||
| In article | View Article | ||
| [7] | M. & C. C. Bin Roslan, “Educational Data Mining for Student Performance Prediction: A Systematic Literature Review (2015-2021),” International Journal of Emerging Technologies in Learning (iJET, 2022. | ||
| In article | View Article | ||
| [8] | T. L. De Andrade, S. J. Rigo, and J. L. V. Barbosa, “Active Methodology, Educational Data Mining and Learning Analytics: A Systematic Mapping Study,” Informatics in Education, vol. 20, no. 2, pp. 171–204, 2021. | ||
| In article | View Article | ||
| [9] | P. Ihantola et al., “Educational data mining and learning analytics in programming: Literature review and case studies,” in ITiCSE-WGP 2015 - Proceedings of the 2015 ITiCSE Conference on Working Group Reports, Association for Computing Machinery, Inc, Jul. 2015, pp. 41–63. | ||
| In article | View Article | ||
| [10] | K. Petersen, S. Vakkalanka, and L. Kuzniarz, “Guidelines for conducting systematic mapping studies in software engineering: An update,” Inf Softw Technol, vol. 64, pp. 1–18, Aug. 2015. | ||
| In article | View Article | ||
| [11] | J. T. Rosado, A. P. Payne, and C. B. Rebong, “EMineProve: Educational Data Mining for Predicting Performance Improvement Using Classification Method,” in IOP Conference Series: Materials Science and Engineering, Institute of Physics Publishing, Oct. 2019. | ||
| In article | View Article | ||
| [12] | M. V. Pagudpud, T. T. Palaoag, and L. M. Padirayon, “Mining the National Career Assessment Examination Result Using Clustering Algorithm,” in IOP Conference Series: Materials Science and Engineering, Institute of Physics Publishing, Mar. 2018. | ||
| In article | View Article | ||
| [13] | M. V. Amazona and A. A. Hernandez, “Modelling student performance using data mining techniques: Inputs for academic program development,” in ACM International Conference Proceeding Series, Association for Computing Machinery, May 2019, pp. 36–40. | ||
| In article | View Article | ||
| [14] | E. Rivera Jorda and A. R. Raqueno, “Predictive Model for the Academic Performance of the Engineering Students Using CHAID and C 5.0 Algorithm,” 2019. [Online]. Available: http://www.irphouse.com. | ||
| In article | |||
| [15] | A. Garcia and S. M. Bongo, “A Predictive Analysis Approach on the Academic Performance of BSIT Students Basis for Teaching-Learning Augmentation Program,” in 2021 4th International Conference on Information Communication and Signal Processing, ICICSP 2021, Institute of Electrical and Electronics Engineers Inc., 2021, pp. 588–592. | ||
| In article | View Article PubMed | ||
| [16] | J. A. Costales, M. G. Albino, and T. D. Palaoag, “Students’ Experiences in Using Learning Management System (Canvas): Application of TAM and Sentiment Analysis,” in IEEE Region 10 Annual International Conference, Proceedings/TENCON, Institute of Electrical and Electronics Engineers Inc., 2022. | ||
| In article | View Article | ||
| [17] | J. G. Perez and E. S. Perez, “Predicting Student Program Completion Using Naïve Bayes Classification Algorithm,” International Journal of Modern Education and Computer Science, vol. 13, no. 3, pp. 57–67, 2021. | ||
| In article | View Article | ||
| [18] | C. Cofino, A. Jhone, P. Delima, J. Carlo, and T. Arroyo, “Performance Analysis of Agriculture Students in Adapting to Distance Learning During COVID-19 Pandemic through Education Data Mining (EDM) Technique.” [Online]. Available: https://www.researchgate.net/publication/366016552 | ||
| In article | |||
| [19] | E. E. C. Cornillez Jr., “Mining educational data in predicting the influence of Mathematics on the programming performance of University students,” Indian J Sci Technol, vol. 13, no. 26, pp. 2668–2677, Jul. 2020. | ||
| In article | View Article | ||
| [20] | M. A. Timbal, “Analysis of Student-at-Risk of Dropping out (SARDO) Using decision tree: An Intelligent predictive model for reduction,” Int J Mach Learn Comput, vol. 9, no. 3, pp. 273–278, Jun. 2019. | ||
| In article | View Article | ||
| [21] | J. D. Febro and J. Barbosa, “Mining student at risk in higher education using predictive models,” Journal of Advances in Technology and Engineering Research, vol. 3, no. 4, 2017. | ||
| In article | View Article | ||
| [22] | G. S. Lumacad, J. V. C. Damasing, S. B. M. Tacastacas, and A. R. T. Quipanes, “Analyzing Sensitive Factors Affecting Online Academic Performance in the New Normal: A Machine Learning Perspective,” in 2022 17th Latin American Conference on Learning Technologies, LACLO 2022, Institute of Electrical and Electronics Engineers Inc., 2022. | ||
| In article | View Article | ||
| [23] | S. M. Baylin and L. S. Lomibao, “Modeling Students’ Procrastination Using Gaussian-Bernoulli Mixed Naïve Bayes Method,” Journal of Innovations in Teaching and Learning, vol. 4, no. 1, pp. 7–12, 2024. | ||
| In article | |||
| [24] | C. D. O. Godinez and L. S. Lomibao, “A Gaussian-Bernoulli Mixed Naïve Bayes Approach to Predict Students’ Academic Procrastination Tendencies in Online Mathematics Learning,” no. April, 2022. | ||
| In article | |||
| [25] | R. C. R. Jr., J. D. Raga, and I. V. Cariño, “Visualizing Student Activity in Blended Learning Classroom by Mining Course Log Data,” International Journal of Learning and Teaching, pp. 1–6, 2018. | ||
| In article | View Article | ||
| [26] | L. Johansen and B. Caluza, “J48-Based Decision Tree Algorithm in Detecting Kolb’s Learning Style Preferences of Information Technology Students,” 2023. | ||
| In article | |||
| [27] | M. Collado Almodiel, “Assessing Online Learners’ Access Patterns and Performance Using Data Mining Techniques,” INTERNATIONAL JOURNAL IN INFORMATION TECHNOLOGY IN GOVERNANCE, EDUCATION AND BUSINESS, vol. 3, no. 1, pp. 46–56, 2021. | ||
| In article | View Article | ||
| [28] | C. S. Santiago et al., “Utilization of Writing Assistance Tools in Research in Selected Higher Learning Institutions in the Philippines: A Text Mining Analysis,” International Journal of Learning, Teaching and Educational Research, vol. 20, no. 11, pp. 259–284, Nov. 2023. | ||
| In article | View Article | ||
| [29] | M. Carvalho and R. Cunha, “Student’s Online Learning Readiness in Times of Covid-19: Self-Report of Undergraduate Psychology Students in Portugal: Student’s Online Learning Readiness in times of Covid-19,” in ACM International Conference Proceeding Series, Association for Computing Machinery, Dec. 2020, pp. 120–123. | ||
| In article | View Article | ||
| [30] | R. Asif, A. Merceron, S. A. Ali, and N. G. Haider, “Analyzing undergraduate students’ performance using educational data mining,” Comput Educ, vol. 113, pp. 177–194, Oct. 2017. | ||
| In article | View Article | ||
| [31] | C. Romero and S. Ventura, “Educational data mining: A review of the state of the art,” IEEE Transactions on Systems, Man and Cybernetics Part C: Applications and Reviews, vol. 40, no. 6, pp. 601–618, 2010. | ||
| In article | View Article | ||
Published with license by Science and Education Publishing, Copyright © 2025 Charles Darwin O. Godinez and Laila S. Lomibao
![]() This work is licensed under a Creative Commons Attribution 4.0 International License. To view a copy of this license, visit
http://creativecommons.org/licenses/by/4.0/
This work is licensed under a Creative Commons Attribution 4.0 International License. To view a copy of this license, visit
http://creativecommons.org/licenses/by/4.0/
| [1] | J. Jerrim et al., “E ducation E ndowment Foundation Mathematics Mastery Secondary Evaluation Report Independent evaluators,” 2015. [Online]. Available: www. educationendowmentfoundation.org.uk | ||
| In article | |||
| [2] | H. Aguhayon, R. Tingson, and J. Pentang, “Addressing Students Learning Gaps in Mathematics through Differentiated Instruction,” International Journal of Educational Management and Development Studies, vol. 4, no. 1, pp. 69–87, Mar. 2023. | ||
| In article | View Article | ||
| [3] | “PISA 2022 Results Factsheets Philippines PUBE,” 2023. [Online]. Available: https://oecdch.art/a40de1dbaf/C266. | ||
| In article | |||
| [4] | J. Sarama et al., “Testing a Theoretical Assumption of a Learning-Trajectories Approach in Teaching Length Measurement to Kindergartners,” AERA Open, vol. 7, 2021. | ||
| In article | View Article | ||
| [5] | S., & I. P. S. Baker, Emergence and Innovation in Digital Learning: Foundations and Applications. Athabasca University Press, 2016. | ||
| In article | |||
| [6] | M. Yağcı, “Educational data mining: prediction of students’ academic performance using machine learning algorithms,” Smart Learning Environments, vol. 9, no. 1, Dec. 2022. | ||
| In article | View Article | ||
| [7] | M. & C. C. Bin Roslan, “Educational Data Mining for Student Performance Prediction: A Systematic Literature Review (2015-2021),” International Journal of Emerging Technologies in Learning (iJET, 2022. | ||
| In article | View Article | ||
| [8] | T. L. De Andrade, S. J. Rigo, and J. L. V. Barbosa, “Active Methodology, Educational Data Mining and Learning Analytics: A Systematic Mapping Study,” Informatics in Education, vol. 20, no. 2, pp. 171–204, 2021. | ||
| In article | View Article | ||
| [9] | P. Ihantola et al., “Educational data mining and learning analytics in programming: Literature review and case studies,” in ITiCSE-WGP 2015 - Proceedings of the 2015 ITiCSE Conference on Working Group Reports, Association for Computing Machinery, Inc, Jul. 2015, pp. 41–63. | ||
| In article | View Article | ||
| [10] | K. Petersen, S. Vakkalanka, and L. Kuzniarz, “Guidelines for conducting systematic mapping studies in software engineering: An update,” Inf Softw Technol, vol. 64, pp. 1–18, Aug. 2015. | ||
| In article | View Article | ||
| [11] | J. T. Rosado, A. P. Payne, and C. B. Rebong, “EMineProve: Educational Data Mining for Predicting Performance Improvement Using Classification Method,” in IOP Conference Series: Materials Science and Engineering, Institute of Physics Publishing, Oct. 2019. | ||
| In article | View Article | ||
| [12] | M. V. Pagudpud, T. T. Palaoag, and L. M. Padirayon, “Mining the National Career Assessment Examination Result Using Clustering Algorithm,” in IOP Conference Series: Materials Science and Engineering, Institute of Physics Publishing, Mar. 2018. | ||
| In article | View Article | ||
| [13] | M. V. Amazona and A. A. Hernandez, “Modelling student performance using data mining techniques: Inputs for academic program development,” in ACM International Conference Proceeding Series, Association for Computing Machinery, May 2019, pp. 36–40. | ||
| In article | View Article | ||
| [14] | E. Rivera Jorda and A. R. Raqueno, “Predictive Model for the Academic Performance of the Engineering Students Using CHAID and C 5.0 Algorithm,” 2019. [Online]. Available: http://www.irphouse.com. | ||
| In article | |||
| [15] | A. Garcia and S. M. Bongo, “A Predictive Analysis Approach on the Academic Performance of BSIT Students Basis for Teaching-Learning Augmentation Program,” in 2021 4th International Conference on Information Communication and Signal Processing, ICICSP 2021, Institute of Electrical and Electronics Engineers Inc., 2021, pp. 588–592. | ||
| In article | View Article PubMed | ||
| [16] | J. A. Costales, M. G. Albino, and T. D. Palaoag, “Students’ Experiences in Using Learning Management System (Canvas): Application of TAM and Sentiment Analysis,” in IEEE Region 10 Annual International Conference, Proceedings/TENCON, Institute of Electrical and Electronics Engineers Inc., 2022. | ||
| In article | View Article | ||
| [17] | J. G. Perez and E. S. Perez, “Predicting Student Program Completion Using Naïve Bayes Classification Algorithm,” International Journal of Modern Education and Computer Science, vol. 13, no. 3, pp. 57–67, 2021. | ||
| In article | View Article | ||
| [18] | C. Cofino, A. Jhone, P. Delima, J. Carlo, and T. Arroyo, “Performance Analysis of Agriculture Students in Adapting to Distance Learning During COVID-19 Pandemic through Education Data Mining (EDM) Technique.” [Online]. Available: https://www.researchgate.net/publication/366016552 | ||
| In article | |||
| [19] | E. E. C. Cornillez Jr., “Mining educational data in predicting the influence of Mathematics on the programming performance of University students,” Indian J Sci Technol, vol. 13, no. 26, pp. 2668–2677, Jul. 2020. | ||
| In article | View Article | ||
| [20] | M. A. Timbal, “Analysis of Student-at-Risk of Dropping out (SARDO) Using decision tree: An Intelligent predictive model for reduction,” Int J Mach Learn Comput, vol. 9, no. 3, pp. 273–278, Jun. 2019. | ||
| In article | View Article | ||
| [21] | J. D. Febro and J. Barbosa, “Mining student at risk in higher education using predictive models,” Journal of Advances in Technology and Engineering Research, vol. 3, no. 4, 2017. | ||
| In article | View Article | ||
| [22] | G. S. Lumacad, J. V. C. Damasing, S. B. M. Tacastacas, and A. R. T. Quipanes, “Analyzing Sensitive Factors Affecting Online Academic Performance in the New Normal: A Machine Learning Perspective,” in 2022 17th Latin American Conference on Learning Technologies, LACLO 2022, Institute of Electrical and Electronics Engineers Inc., 2022. | ||
| In article | View Article | ||
| [23] | S. M. Baylin and L. S. Lomibao, “Modeling Students’ Procrastination Using Gaussian-Bernoulli Mixed Naïve Bayes Method,” Journal of Innovations in Teaching and Learning, vol. 4, no. 1, pp. 7–12, 2024. | ||
| In article | |||
| [24] | C. D. O. Godinez and L. S. Lomibao, “A Gaussian-Bernoulli Mixed Naïve Bayes Approach to Predict Students’ Academic Procrastination Tendencies in Online Mathematics Learning,” no. April, 2022. | ||
| In article | |||
| [25] | R. C. R. Jr., J. D. Raga, and I. V. Cariño, “Visualizing Student Activity in Blended Learning Classroom by Mining Course Log Data,” International Journal of Learning and Teaching, pp. 1–6, 2018. | ||
| In article | View Article | ||
| [26] | L. Johansen and B. Caluza, “J48-Based Decision Tree Algorithm in Detecting Kolb’s Learning Style Preferences of Information Technology Students,” 2023. | ||
| In article | |||
| [27] | M. Collado Almodiel, “Assessing Online Learners’ Access Patterns and Performance Using Data Mining Techniques,” INTERNATIONAL JOURNAL IN INFORMATION TECHNOLOGY IN GOVERNANCE, EDUCATION AND BUSINESS, vol. 3, no. 1, pp. 46–56, 2021. | ||
| In article | View Article | ||
| [28] | C. S. Santiago et al., “Utilization of Writing Assistance Tools in Research in Selected Higher Learning Institutions in the Philippines: A Text Mining Analysis,” International Journal of Learning, Teaching and Educational Research, vol. 20, no. 11, pp. 259–284, Nov. 2023. | ||
| In article | View Article | ||
| [29] | M. Carvalho and R. Cunha, “Student’s Online Learning Readiness in Times of Covid-19: Self-Report of Undergraduate Psychology Students in Portugal: Student’s Online Learning Readiness in times of Covid-19,” in ACM International Conference Proceeding Series, Association for Computing Machinery, Dec. 2020, pp. 120–123. | ||
| In article | View Article | ||
| [30] | R. Asif, A. Merceron, S. A. Ali, and N. G. Haider, “Analyzing undergraduate students’ performance using educational data mining,” Comput Educ, vol. 113, pp. 177–194, Oct. 2017. | ||
| In article | View Article | ||
| [31] | C. Romero and S. Ventura, “Educational data mining: A review of the state of the art,” IEEE Transactions on Systems, Man and Cybernetics Part C: Applications and Reviews, vol. 40, no. 6, pp. 601–618, 2010. | ||
| In article | View Article | ||




{kind=link}