Interstitial cystitis (IC) is a chronic inflammatory condition that results in recurring discomfort or pain in the bladder and the surrounding pelvic region. In interstitial cystitis data base (ICDB) cohort study, the main target is to determine the influence of covariates, such as the demographic clinical characteristics of patients, on the longitudinal outcomes including the pain score (p), urinary urgency (u) and urinary frequency (f) which are three main indices reflecting IC symptoms. The ICDB data are mixed (discrete and continuous) longitudinal data. In longitudinal studies the continuous response may be non-normal, heavy tailed for example. The analysis of mixed longitudinal data is challenging due to several inherent features: (1) more than one outcome are followed for each subject over a period of time. (2) The longitudinal outcomes are subject to missingness that may be missing not at random (MNAR). This article proposes the analysis of mixed discrete and heavy tailed longitudinal outcomes subject to MNAR missingness using two different alternative algorithms. The continuous outcome is assumed to follow non-normal heavy tailed distribution. The proposed methodology is an extension of [1] and [2]. The proposed techniques are applied to Interstitial Cystitis data. Also, three simulation studies are conducted to validate the proposed techniques.
Longitudinal data are comprised of repeated observations of one or more outcomes and a set of covariates for many subjects. A special type of longitudinal data is the bivariate or multivariate longitudinal data where more than one outcome is followed and jointly studied. Multivariate longitudinal data are useful to investigate the joint evolution of these responses over time. The scale (discrete/continuous) of multiple longitudinal outcomes is crucial in multivariate longitudinal analysis. Several approaches are used to analyze mixed discrete and continuous longitudinal data. A general approach for jointly modeling mixed discrete and continuous outcomes is to use the location model presented by 3. The base of the location model is to factorize the joint distribution of both outcomes and fit a univariate model to each component of the factorization.
The longitudinal nature renders the data arising from such studies more susceptible to incompleteness. The problem of missingness has been tackled using many approaches, two of them are discussed in depth in this paper: the stochastic EM (SEM) algorithm and the parametric fractional imputation (PFI) algorithm. The stochastic EM (SEM) algorithm is proposed in 4 and developed in 5, 6 and 7. The parametric fractional imputation (PFI) algorithm is introduced in 8, 9, 10 and 11 in the context of cross-sectional studies, and in 12 and 13, 2 for longitudinal data.
Fewer techniques have been available when the continuous outcome violates normality assumption. In many instances, the assumption of normality is not realistic because of the presence of atypical observations. This problem is more severe if data have missing values 6. Shen etal. 14 noted that the impact of the distributional form on results would be crucial in the case of incomplete data. Therefore, fitting different distributions to the outcomes, in the case of missing data, is advantageous. It allows us to study the properties of the proposed techniques when the distribution of the data is misspecified. This enables us to conduct a sensitivity analysis of the results to the distributional assumptions of the responses.
A common alternative to the normal distribution is the heavy tailed distributions. Multivariate heavy tailed distributions are proposed and adapted to replace the traditional multivariate normal distribution 15, 16, 17, 18, 19, 20, 21, 22, 23. A particular heavy tailed distribution is the t distribution that can be expressed as an infinite mixture of normal distributions 24, 25. This idea is first presented in 26 and advocated in longitudinal context by many studies such as 27 and 28. This distinguished expression is merited of using standard techniques adapted for normal cases. Kenward 29 studies the sensitivity of the selection model under both normality and t distributional assumptions. Gad and Ahmed 6 investigate the effect of the distributional assumptions of the parameters estimates, obtained by the SEM algorithm, in the existence of intermittent missingness assuming both normal and heavy tailed t distribution.
The purpose of this paper is twofold. The first is to extend the joint analysis of mixed discrete and continuous longitudinal data subject to nonignorable missingness assuming non-Gaussian distributions for the continuous outcome; in particular under heavy tailed distributions. To the best of our knowledge, the SEM algorithm and the PFI algorithm have not been applied in the context of mixed discrete and continuous longitudinal outcomes except in 1 and 2 where the normality assumption for the continuous response is imposed. The second is to explore the effect of the distributional assumptions on the SEM and PFI parameters estimates. Therefore, the change of distributional assumption is adopted as a sensitivity tool.
The rest of the paper is organized as follows. Notations and model assumptions are presented in Section 2. The model and proposed methods are highlighted in Section 3. Section 4 is devoted to the application of the SEM algorithm and the PFI algorithm assuming heavy tailed distribution for the continuous outcome. Three simulation studies are presented in Section 5. Application of the proposed techniques on the Interstitial Cystitis Database is discussed in Section 6. Finally, in Section 7, the article ends with few conclusion comments. The Appendix contains some auxiliary tables.
In this article, the same notations of is adopted. The sequences of the continuous and discrete response variables are denoted as  and
and  whilst the sequence
whilst the sequence  is the
is the  -vector of fully observed covariate for the
-vector of fully observed covariate for the  measurement from the
measurement from the  subject at time points
subject at time points  for
for  In vector form, these variables can be expressed as
In vector form, these variables can be expressed as 
 and
and  respectively. The number of time points
respectively. The number of time points  may be common (n) for all individuals.
may be common (n) for all individuals.
A sequence of discrete variable  is assumed to be a realization of independent sample Poisson distribution with parameter
is assumed to be a realization of independent sample Poisson distribution with parameter 
 Let
Let  be a Poisson random variable with parameter
be a Poisson random variable with parameter  that controls the correlation structure of the discrete responses. It is postulated that
that controls the correlation structure of the discrete responses. It is postulated that  is a linear combination of the independent Poisson random variables, that is
is a linear combination of the independent Poisson random variables, that is
 | (1) |
where a is a tuning integer parameter that controls the over-dispersion of the data. It can be seen, from Eq. (1), that 
 and
and  for
for  which means the larger values of a, the greater the variance of
which means the larger values of a, the greater the variance of  Note that
Note that  is always assumed to be positive.
is always assumed to be positive.
Using log-linear model, the possible relationship between E(X) and E(Y/X) and the matrix of covariates Z can be modelled as
 |
While the general linear model is adopted for linking the conditional expectation E(y/x) to the matrix Z.
The conditional distribution of the  given
given  is presumed to depend on conditional mean
is presumed to depend on conditional mean  and conditional covariance matrix
and conditional covariance matrix  The conditional mean
The conditional mean  is presumed to take the form
is presumed to take the form
 | (2) |
where  and
and 
To model the covariance between mixed discrete and continuous longitudinal outcomes, It is assumed that
 | (3) |
where 
 are constants,
are constants, 
 are linear effects of
are linear effects of  on
on  and
and  respectively,
respectively,  are random errors and
are random errors and 
 are the parameters that control the effect of
are the parameters that control the effect of  on
on 
From Eq. (3) the covariance between any two measurements of the discrete and continuous responses, for the same individual, at any time point  can be formulated as:
can be formulated as:
 | (4) |
Using the log-linear model the relationship between  and the covariate
and the covariate  is modeled whilst the general linear model is employed to model the relationship between the response
is modeled whilst the general linear model is employed to model the relationship between the response  and the covariate
and the covariate  i.e.
i.e.
 | (5) |
where  and
and  are the mean parameters for the discrete response and
are the mean parameters for the discrete response and  is its counterpart for the continuous response. Let
is its counterpart for the continuous response. Let  and
and  denote the vectors of parameters for
denote the vectors of parameters for  and
and  respectively.
respectively.
Substituting Eq. (5) in Eq. (1) gives
 |
substituting Eq. (4), Eq. (5) in Eq. (2), it can be shown that
 | (6) |
Yang and Kang 1 shows that from Eq.(6) the conditional expectation  equals
equals
 |
where 
 and
and 
Assuming missingness,  can be classified into two sub-matrices
can be classified into two sub-matrices  and
and  where
where  represent the observed part, while
represent the observed part, while  and
and  denote the missing observations. let
denote the missing observations. let  and
and  be two binary variables, combined into
be two binary variables, combined into  vectors
vectors  and
and  representing the missingness process in
representing the missingness process in  and parameterized by
and parameterized by  and
and  respectively.
respectively.  takes value 1 if
takes value 1 if  is observed and 0 otherwise.
is observed and 0 otherwise.  is defined similarly for the discrete variable
is defined similarly for the discrete variable  Both
Both  and
and  are assumed to follow Bernoulli distribution with a probability
are assumed to follow Bernoulli distribution with a probability  and
and  respectively.
respectively.
Based on the selection model of Diggle and Kenward 30, the joint density function of the outcomes  and response indicators
and response indicators  can be factorized as
can be factorized as
 | (7) |
where
 |
and  is the integer part of
is the integer part of 
The probability of missingness for each missingness process can be modeled using logistic models depending on the measurements at the time of missingness 

 and a set of unknown parameters
and a set of unknown parameters  and the logistic models can be schematized as
and the logistic models can be schematized as
 | (8) |
The probabilities of missingness depends on the observations at the time of missingness, such a type of missingness is termed as missing not at random 31.
The observed joint distribution function  can be obtained as
can be obtained as
 |
The observed data log-likelihood function is proportional to  i.e.
i.e.
 |
where  is the whole set of parameters pertaining to
is the whole set of parameters pertaining to  and
and  and
and  Calculating the Integrations over the missing part is commonly not possible thereby we exploit the ECM algorithm of 32. The stochastic variants of the ECM algorithm can be used to obviate the integrations entailed in the E-step of the ECM algorithm. However, the key assumptions of this estimation process are
Calculating the Integrations over the missing part is commonly not possible thereby we exploit the ECM algorithm of 32. The stochastic variants of the ECM algorithm can be used to obviate the integrations entailed in the E-step of the ECM algorithm. However, the key assumptions of this estimation process are
1. The correct specification of the missingness processes.
2. The correct specification of the responses distributions.
Since both outcomes are not fully observed, the correct distributions of the different outcomes are not known. Many studies criticize the selection model with its sensitivity on the distributional assumptions and recommend studying the impact of changing the responses’ distributions on the gained results. See 33, 34 and the discussion of 30. Therefore, it is tempted to incorporate a sensitivity analysis when treating the missingness problem. This can be accomplished by fitting different distributions to the responses and investigating the effect of distribution misspecification on the gained parameters.
Yaseen and Gad 2 introduced the SEM algorithm and the PFI algorithm to analyze mixed discrete and continuous (normally distributed) longitudinal data subject to non-random missingness. We extend both algorithms to the heavy tailed distribution family for the continuous response keeping the Poisson assumption for the discrete outcome.
A family of heavy tailed distribution can be expressed as infinite mixtures of normal distributions as
 | (9) |
where  is normal distribution with mean
is normal distribution with mean  and covariance matrix
and covariance matrix  and
and  is a known distribution 28. If
is a known distribution 28. If  has gamma distribution with parameters
has gamma distribution with parameters 
 follows multivariate t distribution with mean parameter
follows multivariate t distribution with mean parameter  scale matrix
scale matrix  and degree of freedom
and degree of freedom  i.e.
i.e.
 |
where 
Adopting  as a mixing distribution as in (9), the complete data for the
as a mixing distribution as in (9), the complete data for the  subject are
subject are  whilst
whilst  represent the missing data. The complete density function can be written as
represent the missing data. The complete density function can be written as
 |
and the complete log-likelihood function can be then
 | (10) |
Maximizing  can be performed by separately maximizing
can be performed by separately maximizing 
 and
and  if
if  is known as
is known as  has no information about
has no information about  and
and  Otherwise the four components of the right hand side of (10) are required to be maximized. The MLE estimates can be obtained using the ECM algorithm by maximizing the expectation of the complete log-likelihood function given the observed data and current estimates:
Otherwise the four components of the right hand side of (10) are required to be maximized. The MLE estimates can be obtained using the ECM algorithm by maximizing the expectation of the complete log-likelihood function given the observed data and current estimates:
 |
and our primary interest is to get the MLE’s of  and
and 
The SEM algorithm and the PFI algorithm can be adapted to get the parameters estimates by approximating the E-step of the ECM algorithm as follows.
The SEM Algorithm
The SEM algorithm approximates the E-step by iterating the S-step and M-step specified as follows
The S-Step
The S-step involves simulating the missing data  for the
for the  subject from their conditional distribution given the observed data and current estimates;
subject from their conditional distribution given the observed data and current estimates;  A proper factorization is
A proper factorization is
 |
taking into account the independency between  and
and  and also between
and also between  and
and 
Since we need to simulate from three conditional distributions, the S-step is classified into three sub-steps, whence sequential sampling technique is conducted.
S1-step
In the first sub step, the missing discrete vector for the  subject
subject  is imputed at the
is imputed at the  iteration from
iteration from  Details of the simulation procedures can be found in 2. Let the simulated vector at the
Details of the simulation procedures can be found in 2. Let the simulated vector at the  iteration be denoted as
iteration be denoted as 
S2-step
The second step entails simulating  from
from  Markov Chain Monte Carlo techniques are adopted if direct simulation is not applicable. If
Markov Chain Monte Carlo techniques are adopted if direct simulation is not applicable. If  has gamma distribution with parameters
has gamma distribution with parameters  then it is easy to prove that the conditional distribution
then it is easy to prove that the conditional distribution  follows also gamma distribution with parameters
follows also gamma distribution with parameters  25. The simulated value for the
25. The simulated value for the  subject is termed as
subject is termed as 
S3-step
In the last sub-step,  is simulated from the density
is simulated from the density  depending on the previous simulated values as presented in 2. The simulated vector is denoted as
depending on the previous simulated values as presented in 2. The simulated vector is denoted as 
The simulated data in addition to the observed data constitute a Pseudo complete data and the Q-function can be then approximated at the  iteration as
iteration as
 |
The M-step
After performing the S-step, the Q-function  is maximized using conditional maximization procedures as follows.
is maximized using conditional maximization procedures as follows.
1. In the first sub-step parameters pertaining to the discrete response are being updated using the generalized linear model as presented in 2.
2. In the second sub-step parameters of the continuous response,  and the covariance parameters are updated conditionally on the current estimates of the parameters pertaining to discrete response. If the conditional distribution
and the covariance parameters are updated conditionally on the current estimates of the parameters pertaining to discrete response. If the conditional distribution  follows multivariate t distribution and the continuous response is modelled using the general linear model as in (5), then the errors
follows multivariate t distribution and the continuous response is modelled using the general linear model as in (5), then the errors  of model (5) follows multivariate normal distribution, i.e.
of model (5) follows multivariate normal distribution, i.e.
 |
According to 25 and 6, if we transform 
 and
and  as
as
 |
then the conditional distribution  follows the traditional multivariate normal distribution with conditional mean
follows the traditional multivariate normal distribution with conditional mean  and conditional covariance
and conditional covariance  whence the Jennrich-Scluchter algorithm 35 can be used to maximize
whence the Jennrich-Scluchter algorithm 35 can be used to maximize  allowing for different covariance structures pertaining to continuous variable.
allowing for different covariance structures pertaining to continuous variable.
3. In the last sub-step, the vector of parameters τ are updated. Since both indicator variables are binary, the iterative reweighted least square method (IRLS) can be employed to find the MLE’s.
The PFI Algorithm
The PFI algorithm is executed in the following steps:
1. For each missingness vector;  , K imputed vectors are simulated from the conditional distribution of the missing data given the observed data and current estimates
, K imputed vectors are simulated from the conditional distribution of the missing data given the observed data and current estimates  There is no need to change the imputed values except only in two cases. The first case occurs in the first part of the PFI algorithm which corresponds to the burn-in period of the SEM algorithm. The other case is explained in the third step.
There is no need to change the imputed values except only in two cases. The first case occurs in the first part of the PFI algorithm which corresponds to the burn-in period of the SEM algorithm. The other case is explained in the third step.
2. Using the  imputed vectors,
imputed vectors,  for the vectors of missingness for the
for the vectors of missingness for the  individual, the
individual, the  replicated data are
replicated data are  Given the
Given the  replicated data
replicated data  and the current estimates
and the current estimates  ,
,  a fractional weight
a fractional weight  is calculated at the
is calculated at the  iteration for each replicated data
iteration for each replicated data  as
as
 |
where  ,
,  and
and  are the initial estimates.
are the initial estimates.
3. The missing vectors for the  subject are re-simulated if any of the fractional weights
subject are re-simulated if any of the fractional weights  exceeds the fraction
exceeds the fraction  where c is a fixed constant. This step is essential to avoid unreasonable values in the simulation step and to prevent outliers to dominate the estimation process.
where c is a fixed constant. This step is essential to avoid unreasonable values in the simulation step and to prevent outliers to dominate the estimation process.
4. The following step is to incorporate the fractional weights in the approximation of the E-step using the weighted mean of the complete density functions calculated based on all the  replicated data as follows
replicated data as follows
 |
 |
 |
and then
 |
5. The algorithm alternates between the previous steps till convergence. The convergence is achieved when the difference between two successive estimates is less than  a pre-specified stopping criterion.
a pre-specified stopping criterion.
Three simulation studies have been performed. The first simulation study aims to validate the SEM algorithm and the PFI methods under heavy tailed assumption. The second simulation study investigates the effect of misspecification of normal assumption for the continuous outcome on the SEM and PFI estimates. The distribution of the continuous outcome is treated as a heavy tailed variable despite it was originally generated from normal process. The last simulation study reverses the order of misspecification and measures the effect of misspecification of the heavy tailed assumption by analyzing the continuous outcome generated from multivariate t-distribution as multivariate normal variate.
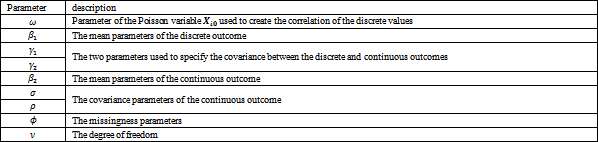
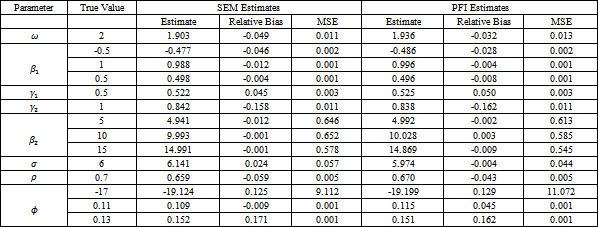
5.1. The First Simulation StudyIn this part, the behavior of the SEM algorithm and the PFI algorithm is studied assuming multivariate Poisson distribution for the discrete outcome and multivariate t distribution for the continuous one. Samples of 500 subjects are generated and constructed as bivariate mixed discrete and continuous outcomes. Five covariates have been used. The covariate matrix Z with five independent variables are generated from the normal distribution with a mean of 3 and a variance of 0.25. A description of the study parameters is given in Table 1. The parameters are fixed at 






 The degree of freedom
The degree of freedom  is set to 5 and is assumed either to be known or estimated from the data. The autoregressive covariance structure is adopted for the continuous longitudinal outcome with
is set to 5 and is assumed either to be known or estimated from the data. The autoregressive covariance structure is adopted for the continuous longitudinal outcome with  and
and  A unified logistic model is used to generate the missingness in both outcomes with parameters
A unified logistic model is used to generate the missingness in both outcomes with parameters  as in Eq. (8). The burn-in period for the SEM algorithm is chosen with length 250 to all parameters. For the PFI algorithm, the number of replicates K is set to five. We choose
as in Eq. (8). The burn-in period for the SEM algorithm is chosen with length 250 to all parameters. For the PFI algorithm, the number of replicates K is set to five. We choose  The first stage length is 10 iterations. Table 2 and Table 3 present the study results.
The first stage length is 10 iterations. Table 2 and Table 3 present the study results.
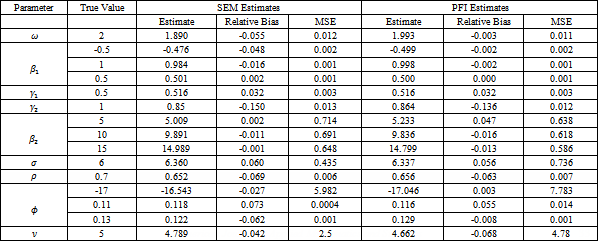
The results highlight that the behavior of the SEM algorithm and the PFI algorithm under heavy tailed assumptions is reasonable. All the parameters have low relative bias (less than 0.20). The performance of the SEM algorithm and the PFI algorithm is alike except for that the relative bias for most of the mean parameters using the PFI algorithm is relatively lower than its counterpart for the SEM algorithm. However, the MSE for the variance parameter  under the SEM algorithm is lower than the MSE under the PFI algorithm. Overall, the performance of both algorithms is similar whether the degree of freedom is known or not.
under the SEM algorithm is lower than the MSE under the PFI algorithm. Overall, the performance of both algorithms is similar whether the degree of freedom is known or not.
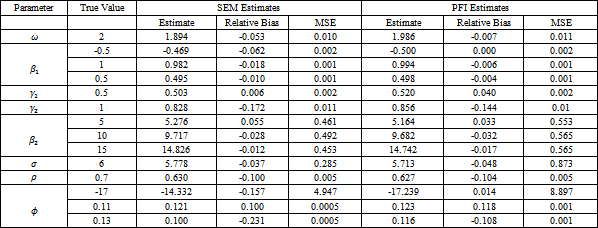
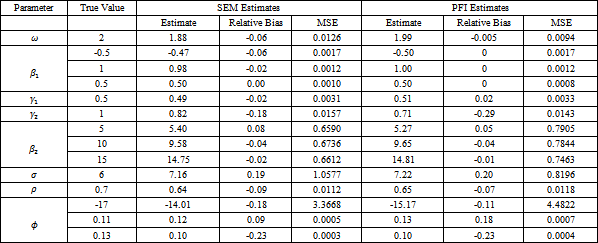
The aim of this part is to study the sensitivity of the SEM and PFI estimates against misspecification of the distributional assumption. We simulate the continuous outcome assuming multivariate normal distribution but then we treat it as it follows multivariate t distribution and apply the SEM algorithm and the PFI algorithm in the settings of heavy tailed case. The degree of freedom is assumed to be fixed at values 5 and 15. The results are presented in Table 4 and Table 5.
We compare the results of the above tables with the results of the similar simulation study conducted in 2, Table A-1 in the Appendix, where the distribution of the continuous outcome is well specified, i.e. the continuous outcome is generated and analyzed assuming the correct distribution which is multivariate normal. The comparison presents that the MSE for all estimates grows in size or keeps at its value. This note is clearer in the estimates of the parameters pertaining to continuous outcome using the PFI algorithm. For the relative bias, we can classify the parameters to three different groups. The first group includes the parameters estimates that almost have no change in their values. This group includes most of the parameters estimates which are  for the SEM and PFI algorithm. The second group contains
for the SEM and PFI algorithm. The second group contains  that relatively grows in size for both the SEM algorithm and the PFI algorithm. The last group entails only
that relatively grows in size for both the SEM algorithm and the PFI algorithm. The last group entails only  that has smaller value for the both algorithms. In general, the absolute change in the relative bias is small for the SEM algorithm and the PFI algorithm. There is no much change comparing the results at different values for the degree of freedom.
that has smaller value for the both algorithms. In general, the absolute change in the relative bias is small for the SEM algorithm and the PFI algorithm. There is no much change comparing the results at different values for the degree of freedom.
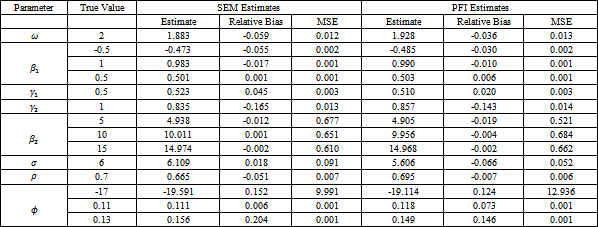
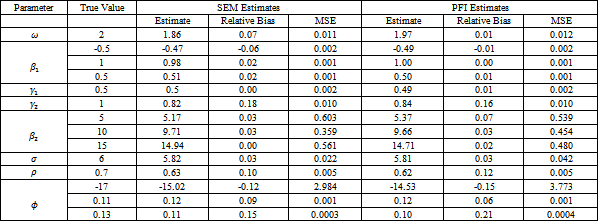
We reverse the order of distribution misspecification. Data are generated assuming multivariate Poisson distribution for the discrete outcome and multivariate t distribution using the same settings of the above simulation study with degree of freedom equal to 5. The SEM algorithm and the PFI algorithm are applied treating the continuous outcome as normal distributed variable. The results are presented in Table 6.
Results from this study and results from Table 2 are brought together and contrasted. Some notes can be concluded. The relative bias for the parameters under misspecification of multivariate t distribution hardly differs from its counterpart under well-specification of multivariate t distribution. The exception for that is the variance parameter  where its absolute relative bias jumps form .03, .04 to .19, .20 for the SEM and PFI algorithms respectively. For the MSE values, the estimates under misspecification of the multivariate t distribution are higher or the same as the MSE values compared to well-specification case.
where its absolute relative bias jumps form .03, .04 to .19, .20 for the SEM and PFI algorithms respectively. For the MSE values, the estimates under misspecification of the multivariate t distribution are higher or the same as the MSE values compared to well-specification case.
The main conclusion of the sensitivity simulation studies is that misspecification of the distribution of the continuous outcome does not affect the relative bias of the estimates- except for the variance parameter. However, the MSE grows in size which leads into a loss of significance for truly significant variables.
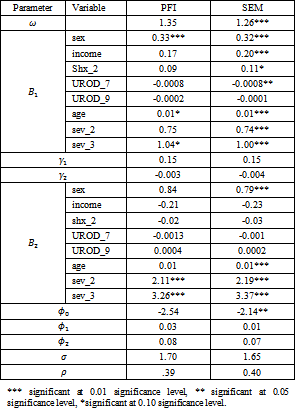
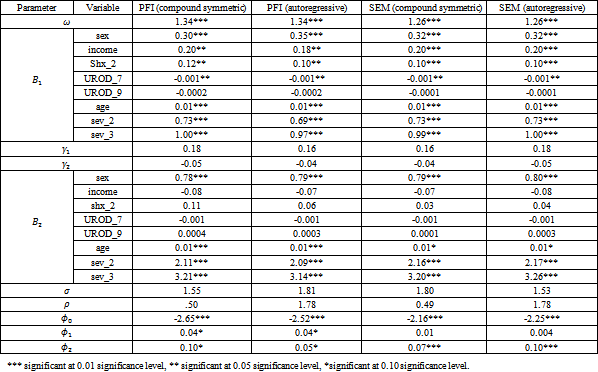
The proposed methods are applied under the assumption of heavy tailed distribution to the Interstitial Cystitis Data Base (ICDB) and the results are compared with the similar results calculated under normality assumptions presented in 2 which is presented in Table A-2 in the Appendix. The ICDB data have been used by 1. The ICDB characteristics are discussed in details in 36. The ICDB data include 637 patient at its baseline. Patients are followed for symptoms of pain, urgency and urinary frequency, from January 1993 to November 1997. Yang and Kang 1 study the joint effect of a group of covariates on the urgency and urinary frequency treating them as continuous and discrete variables respectively. Each of these variables are measured by asking the patients to rate them in the last week on an ordinal scale ranging from 0; for the lowest severity, to 9 which is the maximum severity. In addition, the patients are required to rate the same variables in three consecutive days. The averages of the study variables over the three days are also recorded. The main problem of the data is the high rate of missingness. About 20% of the sample only remained in the study after the 36th month. Therefore, 1 consider only the data gathered in the first 36 months.
In this article we use the same settings of 2 but assuming multivariate heavy tailed distribution for the continuous outcome. Patients with completely missing data or data with outliers in any of the outcomes are omitted from the analysis leading to a reduced sample of 538 patients with maximum observed time points equals 44. A brief description of the covariates is given in Table A-3 in the Appendix.
The analysis starts with similar settings for the first simulation study. The number of replicates for the PFI is set to 3. The standard errors of the estimates are obtained using the Jackknife replication method and the p-values are produced based on the Z-table. The same burn-in period as in the simulation studies are used for the SEM algorithm. The results are presented in Table 7.
For the SEM algorithm, a comparison of the results under normal assumption and heavy tailed assumption shows no difference in terms of the relative bias. For the significance levels, only Shx_2 decreases in its significance from being significant at levels .01 to being significant at level 0.1. Other variables attain its significance at approximately the same levels. For the PFI estimates, the same relative biases are found between the results under different distributional assumptions. However, many variables lose their significance under heavy tailed assumption compared to normal estimates. This includes income, Shx_2, UROD_7, sev_2, in  and sex, age in
and sex, age in  The general conclusion from both results is that assuming heavy tailed distribution instead of normal distribution leads to an increase in the standard errors thereby many variables lose their significance. However, the SEM algorithm is more robust than the PFI algorithm since the change in the significance levels is limited which is a merit over the PFI algorithm. These conclusions coincide with the results of the simulation studies where the change in the distributional assumption affects only the MSE not the relative bias. Other interesting note is the type of missingness the data suffer from. Under multivariate normal assumption, the missingess is considered MNAR according to both SEM and PFI algorithm. In contrast, the nonignorable missingess parameters are insignificant under multivariate t distribution which is also a common result between our study and 6.
The general conclusion from both results is that assuming heavy tailed distribution instead of normal distribution leads to an increase in the standard errors thereby many variables lose their significance. However, the SEM algorithm is more robust than the PFI algorithm since the change in the significance levels is limited which is a merit over the PFI algorithm. These conclusions coincide with the results of the simulation studies where the change in the distributional assumption affects only the MSE not the relative bias. Other interesting note is the type of missingness the data suffer from. Under multivariate normal assumption, the missingess is considered MNAR according to both SEM and PFI algorithm. In contrast, the nonignorable missingess parameters are insignificant under multivariate t distribution which is also a common result between our study and 6.
In this article, the SEM algorithm and the PFI algorithm are extended to heavy tailed case for the continuous outcome. The proposed methods are advantageous in the sense of low relative bias and MSE. The Jennrich-Schluchter algorithm incorporated in the estimation of the covariance parameters permits more flexibility in the specification of the covariance matrix related to the continuous outcome. The sensitivity analysis shows that misspecification of the outcome’s distribution does not affect the values of the estimates. Parameters estimates are still unbiased but their standard errors are increased. This may affect the significance of the variables especially with the PFI algorithm. Yet there are more possible extensions need further investigation. The sensitivity analysis should be investigated against the distributional assumptions for the discrete outcome as well. This is applicable for instance by adopting multivariate negative binominal distribution instead of the multivariate Poisson distribution for the discrete outcome. Validating different mechanisms and forms for the assumed missingness mechanism is also advisable. Another important further point is to represent the covariance of the discrete outcome using a matrix of parameters instead of one as discussed by 37 and 38.
The ICDB data reported here were supplied by the NIDDK Central Repositories. This manuscript does not necessarily reflect the opinions or views of the NIDDK Central Repositories, or the NIDDK.
| [1] | Yang, Y. and J. Kang, Joint analysis of mixed Poisson and continuous longitudinal data with nonignorable missing values. Computational Statistics & Data Analysis, 2010. 54(1): p. 193-207. | ||
| In article | View Article | ||
| [2] | Yaseen, A.S.A. and A.M. Gad, A stochastic variant of the EM algorithm to fit mixed (discrete and continuous) longitudinal data with nonignorable missingness. Communications in Statistics - Theory and Methods, 2019. | ||
| In article | View Article | ||
| [3] | Olkin, I. and R.F. Tate, Multivariate correlation models with mixed discrete and continuous variables. The Annals of Mathematical Statistics, 1961: p. 448-465. | ||
| In article | View Article | ||
| [4] | Celeux, G. and J. Diebolt, The SEM algorithm: a probabilistic teacher algorithm derived from the EM algorithm for the mixture problem. Computational statistics quarterly, 1985. 2(1): p. 73-82. | ||
| In article | |||
| [5] | Gad, A.M. and A.S. Ahmed, Analysis of longitudinal data with intermittent missing values using the stochastic EM algorithm. Computational Statistics & Data Analysis, 2006. 50(10): p. 2702-2714. | ||
| In article | View Article | ||
| [6] | Gad, A.M. and A.S. Ahmed, Sensitivity analysis of longitudinal data with intermittent missing values. Statistical Methodology, 2007. 4(2): p. 217-226. | ||
| In article | View Article | ||
| [7] | Gad, A.M. and N.I. EL-Zayat, Fitting Multivariate Linear Mixed Model for Multiple Outcomes Longitudinal Data with Non-ignorable Dropout. International Journal of Probability and Statistics, 2018. 7(4): p. 97-105. | ||
| In article | |||
| [8] | Kim, J.K. and W. Fuller, Parametric fractional imputation for missing data analysis. Joint Statistical Meeting Proceedings, 2008: p. 158-169. | ||
| In article | |||
| [9] | Kim, J.K., Parametric fractional imputation for missing data analysis. Biometrika, 2011. 98(1): p. 119-132. | ||
| In article | View Article | ||
| [10] | Kim, J.Y. and J.K. Kim, Parametric fractional imputation for nonignorable missing data. Journal of the Korean Statistical Society, 2012. 41(3): p. 291-303. | ||
| In article | View Article | ||
| [11] | Kim, J.K. and M. Hong, Imputation for statistical inference with coarse data. Canadian Journal of Statistics, 2012. 40(3): p. 604-618. | ||
| In article | View Article | ||
| [12] | Yang, S., J.-K. Kim, and Z. Zhu, Parametric fractional imputation for mixed models with nonignorable missing data. Statistics and Its Interface, 2013. 6(3): p. 339-347. | ||
| In article | View Article | ||
| [13] | Yaseen, A. S., Gad, A. M., & Ahmed, A. S, Maximum Likelihood Approach for Longitudinal Models with Nonignorable Missing Data Mechanism Using Fractional Imputation. American Journal of Applied Mathematics and Statistics, 2016. 4(3): p. 59-66. | ||
| In article | |||
| [14] | Shen, S., C. Beunckens, C. Mallinckrodt, and G. Molenberghs, A local influence sensitivity analysis for incomplete longitudinal depression data. Journal of biopharmaceutical statistics, 2006. 16(3): p. 365-384. | ||
| In article | View Article PubMed | ||
| [15] | Pinheiro, J.C., C. Liu, and Y.N. Wu, Efficient algorithms for robust estimation in linear mixed-effects models using the multivariate t distribution. Journal of Computational and Graphical Statistics, 2001. 10(2): p. 249-276. | ||
| In article | View Article | ||
| [16] | Wang, W.-L. and T.-H. Fan, Estimation in multivariate t linear mixed models for multiple longitudinal data. Statistica Sinica, 2011: p. 1857-1880. | ||
| In article | View Article PubMed | ||
| [17] | Luo, S., J. Ma, and K.D. Kieburtz, Robust Bayesian inference for multivariate longitudinal data by using normal/independent distributions. Statistics in medicine, 2013. 32(22): p. 3812-3828. | ||
| In article | View Article PubMed | ||
| [18] | Wang, W.-L., T.-I. Lin, and V.H. Lachos, Extending multivariate-t linear mixed models for multiple longitudinal data with censored responses and heavy tails. Statistical methods in medical research, 2018. 27(1): p. 48-64. | ||
| In article | View Article PubMed | ||
| [19] | Achcar, J.A., E.A. Coelho-Barros, J.R.T. Cuevas, and J. Mazucheli, Use of Lèvy distribution to analyze longitudinal data with asymmetric distribution and presence of left censored data. Communications for Statistical Applications and Methods, 2018. 25(1): p. 43-60. | ||
| In article | View Article | ||
| [20] | Lee, D., Y. Lee, M.C. Paik, and M.G. Kenward, Robust inference using hierarchical likelihood approach for heavy-tailed longitudinal outcomes with missing data: An alternative to inverse probability weighted generalized estimating equations. Computational statistics & data analysis, 2013. 59: p. 171-179. | ||
| In article | View Article | ||
| [21] | Wang, W.-L., Mixture of multivariate t nonlinear mixed models for multiple longitudinal data with heterogeneity and missing values. TEST, 2018. 28: p. 1-27. | ||
| In article | View Article | ||
| [22] | Wang, W.-L. and T.-H. Fan, Bayesian analysis of multivariate t linear mixed models using a combination of IBF and Gibbs samplers. Journal of Multivariate Analysis, 2012. 105(1): p. 300-310. | ||
| In article | View Article | ||
| [23] | Wang, W.L. and T.I. Lin, Multivariate t nonlinear mixed-effects models for multi-outcome longitudinal data with missing values. Statistics in medicine, 2014. 33(17): p. 3029-3046. | ||
| In article | View Article PubMed | ||
| [24] | Peel, D. and G.J. McLachlan, Robust mixture modelling using the t distribution. Statistics and computing, 2000. 10(4): p. 339-348. | ||
| In article | View Article | ||
| [25] | McLachlan, G. and T. Krishnan, The EM algorithm and extensions. Vol. 382. 2007: John Wiley & Sons. | ||
| In article | View Article | ||
| [26] | Andrews, D.F. and C.L. Mallows, Scale mixtures of normal distributions. Journal of the Royal Statistical Society. Series B (Methodological), 1974: p. 99-102. | ||
| In article | View Article | ||
| [27] | Meza, C., F. Osorio, and R. De la Cruz, Estimation in nonlinear mixed-effects models using heavy-tailed distributions. Statistics and Computing, 2012. 22(1): p. 121-139. | ||
| In article | View Article | ||
| [28] | Forbes, F. and D. Wraith, A new family of multivariate heavy-tailed distributions with variable marginal amounts of tailweight: application to robust clustering. Statistics and Computing, 2014. 24(6): p. 971-984. | ||
| In article | View Article | ||
| [29] | Kenward, M.G., Selection models for repeated measurements with non-random dropout: an illustration of sensitivity. Statistics in medicine, 1998. 17(23): p. 2723-2732. | ||
| In article | View Article | ||
| [30] | Diggle, P. and M.G. Kenward, Informative drop-out in longitudinal data analysis. Applied statistics, 1994: p. 49-93. | ||
| In article | View Article | ||
| [31] | Little, R.J. and D.B. Rubin, statistical analysis with missing data. 1987, New York: Wiley. | ||
| In article | |||
| [32] | Meng, X.-L. and D.B. Rubin, Maximum likelihood estimation via the ECM algorithm: A general framework. Biometrika, 1993. 80(2): p. 267-278. | ||
| In article | View Article | ||
| [33] | Council, N.R., Principles and methods of sensitivity analyses, in The Prevention and Treatment of Missing Data in Clinical Trials. 2010, National Academies Press (US). | ||
| In article | |||
| [34] | Daniels, M.J., D. Jackson, W. Feng, and I.R. White, Pattern mixture models for the analysis of repeated attempt designs. Biometrics, 2015. 71(4): p. 1160-1167. | ||
| In article | View Article PubMed | ||
| [35] | Jennrich, R.I. and M.D. Schluchter, Unbalanced repeated-measures models with structured covariance matrices. Biometrics, 1986. 42: p. 805-820. | ||
| In article | View Article PubMed | ||
| [36] | Propert, K.J., A.J. Schaeffer, C.M. Brensinger, J.W. Kusek, L.M. Nyberg, and J.R. Landis, A prospective study of interstitial cystitis: results of longitudinal followup of the interstitial cystitis data base cohort. The Journal of urology, 2000. 163(5): p. 1434-1439. | ||
| In article | View Article | ||
| [37] | Karlis, D. and L. Meligkotsidou, Multivariate Poisson regression with covariance structure. Statistics and Computing, 2005. 15(4): p. 255-265. | ||
| In article | View Article | ||
| [38] | Shi, P. and E.A. Valdez, Multivariate negative binomial models for insurance claim counts. Insurance: Mathematics and Economics, 2014. 55: p. 18-29. | ||
| In article | View Article | ||
Published with license by Science and Education Publishing, Copyright © 2022 Abdallah S. A. Yaseen
![]() This work is licensed under a Creative Commons Attribution 4.0 International License. To view a copy of this license, visit
http://creativecommons.org/licenses/by/4.0/
This work is licensed under a Creative Commons Attribution 4.0 International License. To view a copy of this license, visit
http://creativecommons.org/licenses/by/4.0/
| [1] | Yang, Y. and J. Kang, Joint analysis of mixed Poisson and continuous longitudinal data with nonignorable missing values. Computational Statistics & Data Analysis, 2010. 54(1): p. 193-207. | ||
| In article | View Article | ||
| [2] | Yaseen, A.S.A. and A.M. Gad, A stochastic variant of the EM algorithm to fit mixed (discrete and continuous) longitudinal data with nonignorable missingness. Communications in Statistics - Theory and Methods, 2019. | ||
| In article | View Article | ||
| [3] | Olkin, I. and R.F. Tate, Multivariate correlation models with mixed discrete and continuous variables. The Annals of Mathematical Statistics, 1961: p. 448-465. | ||
| In article | View Article | ||
| [4] | Celeux, G. and J. Diebolt, The SEM algorithm: a probabilistic teacher algorithm derived from the EM algorithm for the mixture problem. Computational statistics quarterly, 1985. 2(1): p. 73-82. | ||
| In article | |||
| [5] | Gad, A.M. and A.S. Ahmed, Analysis of longitudinal data with intermittent missing values using the stochastic EM algorithm. Computational Statistics & Data Analysis, 2006. 50(10): p. 2702-2714. | ||
| In article | View Article | ||
| [6] | Gad, A.M. and A.S. Ahmed, Sensitivity analysis of longitudinal data with intermittent missing values. Statistical Methodology, 2007. 4(2): p. 217-226. | ||
| In article | View Article | ||
| [7] | Gad, A.M. and N.I. EL-Zayat, Fitting Multivariate Linear Mixed Model for Multiple Outcomes Longitudinal Data with Non-ignorable Dropout. International Journal of Probability and Statistics, 2018. 7(4): p. 97-105. | ||
| In article | |||
| [8] | Kim, J.K. and W. Fuller, Parametric fractional imputation for missing data analysis. Joint Statistical Meeting Proceedings, 2008: p. 158-169. | ||
| In article | |||
| [9] | Kim, J.K., Parametric fractional imputation for missing data analysis. Biometrika, 2011. 98(1): p. 119-132. | ||
| In article | View Article | ||
| [10] | Kim, J.Y. and J.K. Kim, Parametric fractional imputation for nonignorable missing data. Journal of the Korean Statistical Society, 2012. 41(3): p. 291-303. | ||
| In article | View Article | ||
| [11] | Kim, J.K. and M. Hong, Imputation for statistical inference with coarse data. Canadian Journal of Statistics, 2012. 40(3): p. 604-618. | ||
| In article | View Article | ||
| [12] | Yang, S., J.-K. Kim, and Z. Zhu, Parametric fractional imputation for mixed models with nonignorable missing data. Statistics and Its Interface, 2013. 6(3): p. 339-347. | ||
| In article | View Article | ||
| [13] | Yaseen, A. S., Gad, A. M., & Ahmed, A. S, Maximum Likelihood Approach for Longitudinal Models with Nonignorable Missing Data Mechanism Using Fractional Imputation. American Journal of Applied Mathematics and Statistics, 2016. 4(3): p. 59-66. | ||
| In article | |||
| [14] | Shen, S., C. Beunckens, C. Mallinckrodt, and G. Molenberghs, A local influence sensitivity analysis for incomplete longitudinal depression data. Journal of biopharmaceutical statistics, 2006. 16(3): p. 365-384. | ||
| In article | View Article PubMed | ||
| [15] | Pinheiro, J.C., C. Liu, and Y.N. Wu, Efficient algorithms for robust estimation in linear mixed-effects models using the multivariate t distribution. Journal of Computational and Graphical Statistics, 2001. 10(2): p. 249-276. | ||
| In article | View Article | ||
| [16] | Wang, W.-L. and T.-H. Fan, Estimation in multivariate t linear mixed models for multiple longitudinal data. Statistica Sinica, 2011: p. 1857-1880. | ||
| In article | View Article PubMed | ||
| [17] | Luo, S., J. Ma, and K.D. Kieburtz, Robust Bayesian inference for multivariate longitudinal data by using normal/independent distributions. Statistics in medicine, 2013. 32(22): p. 3812-3828. | ||
| In article | View Article PubMed | ||
| [18] | Wang, W.-L., T.-I. Lin, and V.H. Lachos, Extending multivariate-t linear mixed models for multiple longitudinal data with censored responses and heavy tails. Statistical methods in medical research, 2018. 27(1): p. 48-64. | ||
| In article | View Article PubMed | ||
| [19] | Achcar, J.A., E.A. Coelho-Barros, J.R.T. Cuevas, and J. Mazucheli, Use of Lèvy distribution to analyze longitudinal data with asymmetric distribution and presence of left censored data. Communications for Statistical Applications and Methods, 2018. 25(1): p. 43-60. | ||
| In article | View Article | ||
| [20] | Lee, D., Y. Lee, M.C. Paik, and M.G. Kenward, Robust inference using hierarchical likelihood approach for heavy-tailed longitudinal outcomes with missing data: An alternative to inverse probability weighted generalized estimating equations. Computational statistics & data analysis, 2013. 59: p. 171-179. | ||
| In article | View Article | ||
| [21] | Wang, W.-L., Mixture of multivariate t nonlinear mixed models for multiple longitudinal data with heterogeneity and missing values. TEST, 2018. 28: p. 1-27. | ||
| In article | View Article | ||
| [22] | Wang, W.-L. and T.-H. Fan, Bayesian analysis of multivariate t linear mixed models using a combination of IBF and Gibbs samplers. Journal of Multivariate Analysis, 2012. 105(1): p. 300-310. | ||
| In article | View Article | ||
| [23] | Wang, W.L. and T.I. Lin, Multivariate t nonlinear mixed-effects models for multi-outcome longitudinal data with missing values. Statistics in medicine, 2014. 33(17): p. 3029-3046. | ||
| In article | View Article PubMed | ||
| [24] | Peel, D. and G.J. McLachlan, Robust mixture modelling using the t distribution. Statistics and computing, 2000. 10(4): p. 339-348. | ||
| In article | View Article | ||
| [25] | McLachlan, G. and T. Krishnan, The EM algorithm and extensions. Vol. 382. 2007: John Wiley & Sons. | ||
| In article | View Article | ||
| [26] | Andrews, D.F. and C.L. Mallows, Scale mixtures of normal distributions. Journal of the Royal Statistical Society. Series B (Methodological), 1974: p. 99-102. | ||
| In article | View Article | ||
| [27] | Meza, C., F. Osorio, and R. De la Cruz, Estimation in nonlinear mixed-effects models using heavy-tailed distributions. Statistics and Computing, 2012. 22(1): p. 121-139. | ||
| In article | View Article | ||
| [28] | Forbes, F. and D. Wraith, A new family of multivariate heavy-tailed distributions with variable marginal amounts of tailweight: application to robust clustering. Statistics and Computing, 2014. 24(6): p. 971-984. | ||
| In article | View Article | ||
| [29] | Kenward, M.G., Selection models for repeated measurements with non-random dropout: an illustration of sensitivity. Statistics in medicine, 1998. 17(23): p. 2723-2732. | ||
| In article | View Article | ||
| [30] | Diggle, P. and M.G. Kenward, Informative drop-out in longitudinal data analysis. Applied statistics, 1994: p. 49-93. | ||
| In article | View Article | ||
| [31] | Little, R.J. and D.B. Rubin, statistical analysis with missing data. 1987, New York: Wiley. | ||
| In article | |||
| [32] | Meng, X.-L. and D.B. Rubin, Maximum likelihood estimation via the ECM algorithm: A general framework. Biometrika, 1993. 80(2): p. 267-278. | ||
| In article | View Article | ||
| [33] | Council, N.R., Principles and methods of sensitivity analyses, in The Prevention and Treatment of Missing Data in Clinical Trials. 2010, National Academies Press (US). | ||
| In article | |||
| [34] | Daniels, M.J., D. Jackson, W. Feng, and I.R. White, Pattern mixture models for the analysis of repeated attempt designs. Biometrics, 2015. 71(4): p. 1160-1167. | ||
| In article | View Article PubMed | ||
| [35] | Jennrich, R.I. and M.D. Schluchter, Unbalanced repeated-measures models with structured covariance matrices. Biometrics, 1986. 42: p. 805-820. | ||
| In article | View Article PubMed | ||
| [36] | Propert, K.J., A.J. Schaeffer, C.M. Brensinger, J.W. Kusek, L.M. Nyberg, and J.R. Landis, A prospective study of interstitial cystitis: results of longitudinal followup of the interstitial cystitis data base cohort. The Journal of urology, 2000. 163(5): p. 1434-1439. | ||
| In article | View Article | ||
| [37] | Karlis, D. and L. Meligkotsidou, Multivariate Poisson regression with covariance structure. Statistics and Computing, 2005. 15(4): p. 255-265. | ||
| In article | View Article | ||
| [38] | Shi, P. and E.A. Valdez, Multivariate negative binomial models for insurance claim counts. Insurance: Mathematics and Economics, 2014. 55: p. 18-29. | ||
| In article | View Article | ||