 OPEN ACCESS
OPEN ACCESS  PEER-REVIEWED
PEER-REVIEWED
Comparative Study of Intelligent Prediction Models for Pressure Wave Velocity
A.K. Verma1, , T. N singh2, Sachin Maheshwar1
, T. N singh2, Sachin Maheshwar1
1Department of Mining Engineering, Indian School of Mines – Dhanbad-04, Jharkhand, India
2Department of Earth Sciences, Indian Institute of Technology-Bombay, Powai, Mumbai, India
Abstract
Support Vector Machine (SVM) optimization technique is rapidly gaining attractiveness in the area of geophysics, mining and geomechanics. This paper discusses the importance of SVM for prediction of longitudinal pressure-wave velocity and its advantages over other conventional methods of computing. Pressure-wave measurement, an indicator of peak particle velocity (PPV) during blasting in a mine is an important parameter to be determined to minimize the damage caused by ground vibrations. A number of previous researchers have tried to use different empirical methods to predict pressure-wave. But these empirical methods are less versatile in their applications. The fracture propagation is not only influenced by the physico-mechanical parameters of rock, but they are also affected by the dynamic wave velocity of rock (e.g. compressional wave velocity). Wave velocity measurements have wide applications in the different fields of geophysics. A Support Vector Machine (SVM) model is designed to predict the pressure wave velocity of different rocks. To avoid the blindness in man-made choices of parameters of SVM, we use the chaos optimization algorithm to find the optimal parameters which can help the model to enhance the learning efficiency and capability of prediction. The fracture roughness coefficient and physico-mechanical properties are taken as input parameters and pressure wave velocity as output parameters. The mean absolute percentage error for the pressure wave velocity (PrV) predicted value has been found to be the least (0.258%) as compared to values obtained by Multivariate Regression Analysis (MVRA), Artificial Neural Network (ANN) and Adaptive Neuro Fuzzy Inference System (ANFIS) and generalization capability of the SVM model is found to be very useful for such type of geophysical problems.
At a glance: Figures
Keywords: SVM, ANFIS, ANN, pressure wave velocity, hardness, porosity
Journal of Geosciences and Geomatics, 2014 2 (3),
pp 130-138.
DOI: 10.12691/jgg-2-3-9
Received June 07, 2014; Revised June 16, 2014; Accepted June 17, 2014
Copyright © 2013 Science and Education Publishing. All Rights Reserved.Cite this article:
- Verma, A.K., T. N singh, and Sachin Maheshwar. "Comparative Study of Intelligent Prediction Models for Pressure Wave Velocity." Journal of Geosciences and Geomatics 2.3 (2014): 130-138.
- Verma, A. , singh, T. N. , & Maheshwar, S. (2014). Comparative Study of Intelligent Prediction Models for Pressure Wave Velocity. Journal of Geosciences and Geomatics, 2(3), 130-138.
- Verma, A.K., T. N singh, and Sachin Maheshwar. "Comparative Study of Intelligent Prediction Models for Pressure Wave Velocity." Journal of Geosciences and Geomatics 2, no. 3 (2014): 130-138.
| Import into BibTeX | Import into EndNote | Import into RefMan | Import into RefWorks |
1. Introduction
Use of seismic techniques in geotechnical engineering is increasing day by day to evaluate long-term stability of rock structure. The dynamic behavior of rocks are largely characterized and determined by various techniques. Attempt are made to examine rockbolt enforcement, blasting efficiency of rock by the seismic velocity measurement, estimation of fracture zone developed around the underground opening, determination of degree of rock weathering and characterization of fractured rock mass (Price et.al., 1970; Young et.al., 1985; Hudson et.al., 1980; Karpuz and Pasamehmetoglu, 1997; Boadu, 1997).
Many researchers attempted to study the relation between the rock properties and pressure wave velocity (PrV) and tried to establish relation to the static rock properties. Rock type, density, hardness, porosity, strength properties, temperature, grain size and shape, confining pressure, etc. are the most important factors influencing the pressure-wave velocity. The rocks have been subjected throughout their history to a wide range of diagnostic processes which affect their petro physical and pressure wave properties. Apart from these, fracture properties (roughness, filling material, dip, strike, etc.) also influence the compressive wave velocity in rock. The relation of the seismic velocities in rocks of the western region of the central to density and other physical parameters is discussed by Yudborovsky and Vilenskaya (1962). Aveline et al. (1964) have found lower velocity in weathered granite, as compared to fresh one. Berezkin and Mikhaylov (1964) have revealed linear correlation between density and elastic wave velocities in rocks of the central and eastern region of the Russian platform.
Measurement of wave velocities in rocks as well as in many other materials is available in the literature (Goodman, 1989; Kern, 1990). Prediction of peak particle velocity, an indicator of pressure-wave helps in designing structures near blasting region of surface mines and other applications related to blasting. Long-term stability of rock structures can only be achieved when pressure wave velocity of the rock mass is fully known. Earthquake advance warning is possible by detecting the non-destructive pressure-wave that travel more quickly through the Earth's crust than do the destructive secondary and Rayleigh waves. Determination of pressure-wave enables the development of earthquake resistant buildings.
Due to the fast development of soft computing tools, it is now possible to solve number of complex problems with greater degree of accuracy and authenticity. The soft computing tools like artificial neural network, fuzzy logic, genetic algorithm, etc. have potential to provide rapid, precise and accurate prediction of ground vibration over well-known predictors (Verma 2009, Sinha et al., 2010, Singh et. al, 2004 a, b). ANN approached by many researcher to predict the ground vibration using various parameters and comparing the result from the available predictors justify the superiority of soft computing (Singh and Verma, 2005, Khandelwal and Singh 2006).
Support Vector Machine algorithm is also an appropriate tool to be used for prediction of ground vibration. SVM can provide solutions for highly intricate problems and perform well approximating solutions to all types of optimization problems. These machines (SVMs) are a set of related supervised learning methods used for classification and regression. In simple words, given a set of training examples, each marked as belonging to one of two categories, SVM training algorithm builds a model that predicts whether a new example falls into one category or the other.
In the present work, a SVM model is designed to predict pressure-wave velocity in rock mass taking physico-mechanical properties and fracture roughness coefficient as an input parameter. This paper is mainly focused not only on how to construct the model, but also on how to use this modeling framework to deduce the results and assess the applicability and reliability of the model.
2. Data Set
Present investigation aims at predicting the elastic property of the rocks (pressure-wave velocity), taking physico-mechanical properties and fracture roughness coefficient as inputs. The other parameters (density, hardness, etc.) also influence the pressure wave velocity in rock, but it is uneconomical to obtain all the parameters because they are expensive and time-consuming. On the other hand, some of the parameters are strongly correlated (Hogstrom, 1994). Hence, it is not imperative to use all the variables as input parameters.
In the present investigation SVM model is designed using the 150 data set of three different rock types (Marble, Travertine and Granite), each from different rock class. Hence, following parameters have been taken as input parameters for the network as shown in Table 1.


 PowerPoint Slide
PowerPoint Slide Larger image(png format)
Larger image(png format)
 View current table in a new window
View current table in a new window
Thus, all six parameters are taken as input parameters for the network. Pressure velocity is taken as an output parameter and its range is given in Table 2. Table 3 shows the types and class of rocks used in the study.

 PowerPoint Slide
PowerPoint Slide Larger image(png format)
Larger image(png format) View current table in a new window
View current table in a new window

 PowerPoint Slide
PowerPoint Slide Larger image(png format)
Larger image(png format) View current table in a new window
View current table in a new window3. Multivariate Regression Analysis
PrV (cm/s) = 393.3000 + 133.28122h -524.4707p + 1077.5929 ab + 0.0062UCS-228.2424 d +45.4384frc

) PowerPoint Slide
PowerPoint Slide Larger image(png format)
Larger image(png format)
A residual plot is a graph that shows the residuals on the vertical axis and the independent variable on the horizontal axis. The points in the residual plot are randomly dispersed around the horizontal axis which indicates that a linear regression model is appropriate for the data (Figure 1).
4. Artificial Neural Network
ANN is able to solve difficult problems in a way that resembles human intelligence. Unique about neural networks is their ability to learn by example. Traditional artificial intelligence (AI) solutions rely on symbolic processing of the data, and approach that requires a prior human knowledge about the problem. In addition, neural network’s techniques have an advantage over statistical methods of data classification because they are distributions-free and require not a prior knowledge about the statistical distributions of the classes in the data sources in order to classify them. Unlike these two approaches, ANN is able to solve problems without any a prior assumptions. As long as enough data is available, a neural network will extract any regularity and form a solution.
4.1. Training a NetworkDuring learning of the network, data are processed through the network, until it reaches the output layer (forward pass). In this layer, the output is compared to the measured values (the true output). The difference or error between both is processed back through the network (backward pass), updating the individual weights of the connections and the biases of the individual PEs (Richard and Lippmann, 1991; Monjezi and Dehghani, 2008). The input and output data are mostly represented as vectors called training pairs. The input and output neurons used in the network with 4 hidden layers have been shown in Figure 2.

 PowerPoint Slide
PowerPoint Slide Larger image(png format)
Larger image(png format)5. Adaptive Neuro Fuzzy Inference System
The most popular solution of the fuzzy networks is based on the so-called fuzzy inference system, fuzzy if - then rules and fuzzy reasoning. Such fuzzy inference system implements a nonlinear mapping from the input space to output space. This mapping is accomplished by a number of fuzzy if- then rules, each of which describes the local behavior of the mapping, like it is done in radial basis function networks. The antecedent of the rule defines the fuzzy region in the input space, while the consequent specifies the output of the fuzzy region. There are different solutions of fuzzy inference systems. The most known belongs to the Mamdani fuzzy model. Tsukamoto fuzzy model and Takagi–Sugeno–Kang (TSK) model (Takagi and Sugeno, 1985, Chiu, 1994). In the present work we have considered only TSK model. The network has a multi-layer form as shown in Figure 3.

 PowerPoint Slide
PowerPoint Slide Larger image(png format)
Larger image(png format)
 PowerPoint Slide
PowerPoint Slide Larger image(png format)
Larger image(png format) View current table in a new window
View current table in a new windowOut of 150 data sets available 114 sets were taken for training, 26 data sets for testing and 10 data sets were taken for checking the model. The membership function of each input is tuned using hybrid method consisting of back propagation for the parameters. The computations of the membership function parameters are facilitated by a gradient vector, which provides a measure of how well the FIS (fuzzy inference system) system is modeling the input/output data. For a given set of parameter the numbers of nodes in the training data were found to be 205. Number of linear parameters and non-linear parameters were found to be 98 and 168 respectively. The hypothesized initial number of membership functions and the type used for each input were 10 and Gaussian respectively. Now, the hypothesized FIS model is trained to emulate the training data by modifying the membership function parameters according to the chosen error criterion. A suitable configuration has to be chosen for the best performance of the network. Goal for the error was set to be zero and number of training epochs was given 30. Table 4 shows final configuration for the FIS after the training (Goal was reached after 30 epochs) was complete.
The clustering method used in this paper is Subtractive clustering. The purpose of using clustering method is to identify natural groupings of data from a large set of data set to produce a concise representation of a system’s behavior. ANFIS (adaptive neuro-fuzzy inference system) structure of the model, with four input parameters, one output parameters and five rules are shown in Figure 3.
For checking, 10 data sets have been used in this model apart from 26 testing data sets as validation data set because checking data set is used to control the potential for the model over fitting the data. When checking data is presented to ANFIS as well as training data, the FIS model is selected to have parameter associated with the minimum checking data model error. The basic idea behind using the training data set for model validation. In principle, the model error for the checking data set tends to decrease as the training takes place to the point that over fitting begins, and the model error for the checking data suddenly increases. Also using the checking data set with ANFIS automatically sets the FIS parameters to be those associated with the minimum checking error.

 PowerPoint Slide
PowerPoint Slide Larger image(png format)
Larger image(png format)
 PowerPoint Slide
PowerPoint Slide Larger image(png format)
Larger image(png format)Figure 4 shows the performance graph of the model. It can be seen from the graph that the checking error is reducing continuously as the training of the model is progressing, this indicates that the model is not over fitting the training data set. Figure 5 shows the correlation results between observed and predicted values of pressure wave velocity. The high coefficient of correlation sets indicates the excellent generalization capability of the fuzzy inference system and it can be said that the result obtained are accurate and highly encouraging.
6. Support Vector Machine
Kernel-based techniques (such as support vector machines, Bayes point machines, kernel principal component analysis, and Gaussian processes) represent a major development in machine learning algorithms. Support vector machines (SVM) are a group of supervised learning methods that can be applied to classification or regression.
These machines represent an extension to nonlinear models of the generalized portrait algorithm developed by Vapnik and Lerner (1963). The SVM algorithm is based on the statistical learning theory and the Vapnik–Chervonenkis (VC) dimension. The statistical learning theory, which describes the properties of learning machines that allow them to give reliable predictions, was reviewed by Vapnik (1995). In the current formulation, the SVM algorithm was developed at AT&T Bell Laboratories by Vapnik and Chervonenkis (1991)
A Support Vector Machine (SVM) performs classification by constructing an N-dimensional hyper-plane that optimally separates the data into two categories. Support Vector Machine (SVM) models are a close cousin to classical multilayer perceptron neural networks. Using a kernel function, SVM’s are an alternative training method for polynomial, radial basis function and multilayer perceptron classifiers in which the weights of the network are found by solving a quadratic programming problem with linear constraints, rather than by solving a non-convex, unconstrained minimization problem as in standard neural network training.
In the parlance of SVM, a predictor variable is called an attribute, and a transformed attribute that is used to define the hyper plane is called a feature. The task of choosing the most suitable representation is known as feature selection. A set of features that describe one case (i.e., a row of predictor values) is called a vector. So the goal of SVM modeling is to find the optimal hyper plane that separates clusters of vector in such a way that cases with one category of the target variable are on one side of the plane and cases with the other category are on the other size of the plane. The vectors near the hyper plane are the support vectors. Figure 6 shows an overview of the SVM process.

 PowerPoint Slide
PowerPoint Slide Larger image(png format)
Larger image(png format)Before considering N-dimensional hyper planes, let’s look at a simple 2-dimensional example. Assume we wish to perform a classification, and our data has a categorical target variable with two categories. Also, assume that there are two predictor variables with continuous values. One category of the target variable is represented by rectangles while the other category is represented by ovals.
6.1. SVM and Kernel ParametersTraining an SVM finds the large margin hyper plane and has another set of parameters called hyper parameters: The soft margin constant, C, and any parameters the kernel function may depend on (width of a Gaussian kernel or degree of a polynomial kernel).
Hyper parameters with the soft-margin constant called ‘C’, whose role is illustrated in Figure 7. A smaller value of C (right) allows to ignore points close to the boundary, and increases the margin. The decision boundary between negative examples (red circles) and positive examples (blue crosses) is shown as a thick line. The lighter lines are on the margin (discriminant value equal to -1 or +1). The grayscale level represents the value of the discriminant function, dark for low values and a light shade for high values.
For a large value of C a large penalty is assigned to errors/margin errors. This is seen in the left panel of Figure 7, where the two points closest to the hyper plane affects its orientation, resulting in a hyper plane that comes close to several other data point. When C is decreased (right panel of the figure), those points become margin errors; the hyper plane’s orientation is changed, providing a much larger margin for the rest of the data.

 PowerPoint Slide
PowerPoint Slide Larger image(png format)
Larger image(png format)
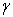 ) for a fixed value of the soft-margin constant. For small values of
) for a fixed value of the soft-margin constant. For small values of 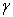 (upper left) the decision boundary is nearly linear. As
(upper left) the decision boundary is nearly linear. As 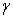 increases the flexibility of the decision boundary increases. Large values of
increases the flexibility of the decision boundary increases. Large values of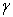 lead to over fitting (bottom)
lead to over fitting (bottom)
 for a fixed value of the soft-margin constant. For small values of (upper left) the decision boundary is nearly linear. As increases the flexibility of the decision boundary increases. Large values of lead to over fitting (bottom)) PowerPoint Slide
PowerPoint Slide Larger image(png format)
Larger image(png format)The parameter of the Gaussian kernel determines the flexibility of the resulting SVM in fitting the data. If this complexity parameter is too large, over fitting will occur (bottom panels in Figure 8).
6.2. Model development for SVMSVM model developed here uses important parameters on which pressure wave velocity mainly depends. The parameters which are taken into account are Compressive strength (UCS in MPa), Density (d in gm/cc), Hardness (h), Porosity (p in %), Absorption (ab in %) and Fracture roughness coefficient (frc). Out of 150 data sets available 114 sets were taken for SVM training, 26 data sets for SVM testing and 10 data sets were taken for SVM checking the model to see its prediction capability. The architecture of SVM established is given in Table 5.
The RBF kernel non-linearly maps samples into a higher dimensional space, so it can handle nonlinear relationships between target categories and predictor attributes; a linear basis function cannot do this. The RBF function has fewer parameters to tune than a polynomial kernel, and the RBF kernel has less numerical difficulties.
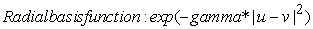 |
Stopping criteria of 0.001 has been chosen that is a tolerance factor that controls when the iterative optimization process stops.
A SVM model is formed by selecting a hyper plane that partitions the data with maximum margin between the feature vectors that define points near overlap. Shrinking heuristic method has been chosen which improves performance by ignoring points that are far from overlapping and which are unlikely to influence the choice of the optimal separating hyper plane. Essentially, shrinking eliminates outlying vectors from consideration. Shrinking heuristics significantly speed up performance when the training data set is large.
The accuracy of an SVM model is largely dependent on the selection of the model parameters such as C, Gamma, P, etc. Two methods for finding optimal parameter values, a grid search and a pattern search has been used. A grid search tries values of each parameter across the specified search range using geometric steps. The range used in this case is between 1 to10. A pattern search (also known as a “compass search” or a “line search”) starts at the center of the search range and makes trial steps in each direction for each parameter. The search range in this paper is 10 and a tolerance of 1.0e-8 has been chosen. If the fit of the model improves, the search center moves to the new point and the process is repeated. If no improvement is found, the step size is reduced and the search is tried again. The pattern search stops when the search step size is reduced to a specified tolerance. In this paper, the grid search is performed first. Once the grid search finished, a pattern search has been performed over a narrow search range surrounding the best point found by the grid search. The grid search may find a region near the global optimum point and the pattern search will then find the global optimum by starting in the right region. The optimized values of C, gamma and P obtained after two searches has been shown in Table 6.
An Epsilon-SVR analysis uses three obtained parameters (C, Gamma and P) so a grid search with 10 intervals required 10*10*10 = 1000 model evaluations (table4). Since cross-validation is used for this model evaluation, the number of actual SVM calculations will be further multiplied by the number of cross-validation folds (typically 4 to 10).

 PowerPoint Slide
PowerPoint Slide Larger image(png format)
Larger image(png format) View current table in a new window
View current table in a new window
 PowerPoint Slide
PowerPoint Slide Larger image(png format)
Larger image(png format) View current table in a new window
View current table in a new window
 PowerPoint Slide
PowerPoint Slide Larger image(png format)
Larger image(png format) View current table in a new window
View current table in a new windowNormalized mean square error (NMSE) was found to be 0.000034 while correlation of coefficient between actual and predicted values was found to be 0.997 as shown in Table 7. 26 out of 150 support vectors obtained are given in Table 8 which also shows the percentage error of predicted PrV for 26 testing support vectors.

 PowerPoint Slide
PowerPoint Slide Larger image(png format)
Larger image(png format)
 PowerPoint Slide
PowerPoint Slide Larger image(png format)
Larger image(png format) View current table in a new window
View current table in a new windowFigure 9 shows that the correlation coefficient obtained for SVM. The r2 value obtained is 0.9998, which is very high and it shows the strong predictive capability of SVM over other conventional methods as shown in Table 9. The relationship obtained between observed and predicted values is,
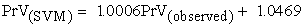 |
It clearly shows that PrV values predicted using SVM are in good agreement to the observed values.

 PowerPoint Slide
PowerPoint Slide Larger image(png format)
Larger image(png format) View current table in a new window
View current table in a new window7. Conclusion
Because of structural complexity of rock mass and its consequent influence on the pressure wave velocity, it often shows highly nonlinear characteristics, which cannot be described by the classical mathematical methods. Based on the support vector machine (SVM) theory, this paper predicts the pressure wave velocity which proved more effective and accurate than the conventional MVRA, ANN and ANFIS. The mean absolute percentage of errors obtained using SVM, ANFIS, ANN and MVRA are 0.258, 0.309, 0.583 and 0.769 respectively. Considering the complexity between inputs and outputs the result obtained are highly encouraging and proves the superiority of SVM over ANN, ANFIS and MVRA. Using SVM as a tool, the correct prediction of pressure wave velocity can be made which can save the surface structures in the vicinity of blasting site from possible damage. This tool can be used for optimization of PrV with greater degree of confidence due to its robustness and unbiased prediction capability.
References
| [1] | Aveline M., 1964. Experimental results on the relation between micro-fissuration and speed of propagation of ultrasounds in the granites of Sidbore, Sci. Terre. 9 (4), 439-448. | ||
 In article In article | |||
| [2] | Berezkin V M & Mikhaylov I N.,1964. On the correlational relationship between the density of rocks and their velocities of elastic wave propagation for the central and eastern regions of Russian platform, Geofiz, Razvedka. 16, 83-91. | ||
| In article | |||
| [3] | Boadu, F.K., 1997. Fractured rock mass characterization parameters and seismic properties: analytical studies. J. Appl. Geophys. 36, 1-19. | ||
| In article | CrossRef | ||
| [4] | Chiu S., 1994. Fuzzy model identification based on cluster estimation. Journal of Intelligent and fuzzy systems. 2 (3), 267-278. | ||
| In article | |||
| [5] | Goodman R.E., 1989. Introduction to Rock Mechanics. (2nd ed.), Wiley, New York, 562. | ||
| In article | |||
| [6] | H. Kern, 1990. Laboratory seismic measurements: an aid in the interpretation of seismic field data, Terra Nova. 2, 203-617. | ||
| In article | CrossRef | ||
| [7] | Hogstrom K., 1994. A study on strength parameter for aggregate from south western Sweden rocks, Res Rep. (Chamer Univ of Technology, Goteborg, Sweden), 123-134. | ||
| In article | |||
| [8] | Hudson, T.A., Jones, E.T.W., New, B.M., 1980. P-wave velocity measurements in a machine bored chalk tunnels. Q. J. Eng. Geol, 13, 33-43. | ||
| In article | CrossRef | ||
| [9] | Karpuz, C. and Pasamehmetoglu, A.G., 1997. Field characterization of weathered Ankara andesites. Eng. Geol. 46, 1-17. | ||
| In article | CrossRef | ||
| [10] | Khandelwal, M. and Singh T.N., 2006. Prediction of blast induced ground vibrations and frequency in opencast mine: a neural network approach. Journal of sound and vibration. 289 (4), 711-725. | ||
| In article | CrossRef | ||
| [11] | Monjezi, M. and Dehghani,H., 2008. Evaluation of effect of blasting pattern parameters on back break using neural networks. Int. Jol. of Rock Mech. and Mining Sci. 45 (8), 1446-1453. | ||
| In article | CrossRef | ||
| [12] | Price, D.G., Malone, A.W., Knill, T.L., 1970. The application of seismic methods in the design of rock bolt system. Proc. 1st Int. Congr., Int. Assoc. Eng. Geol., 2, 740-752. | ||
| In article | |||
| [13] | Richard, MD and Lippmann, RP, 1991. Neural network classifiers estimate Bayesian a posteriori probabilities, Neural computation. 3 (4), 461-483 | ||
| In article | CrossRef | ||
| [14] | S Sinha, TN Singh, VK Singh, AK Verma, 2010. Epoch determination for neural network by self-organized map (SOM). Computational Geosciences. 14 (1), 199-206. | ||
| In article | CrossRef | ||
| [15] | Singh, T.N., Kanchan, R. and Verma, A.K., 2004b. Prediction of blast induced ground vibration and frequency using an artificial intelligence technique, Int J. Noise and Vibration Worldwide, Multi Science Pub. UK, 35 (11), 7-14. | ||
| In article | |||
| [16] | Singh, T.N. and Verma, A.K., 2005. Prediction of creep characteristic of rock under varying environment. Environmental Geology. 48 (4), 559-568 | ||
| In article | CrossRef | ||
| [17] | Singh, T.N., Kanchan, R., Saigal, K. and Verma, A.K. 2004a. Prediction of P-wave Velocity and Anisotropic properties of rock using Artificial Neural Networks technique, J. Scientific and Industrial research, CSIR Publication, 63 (1), 32-38. | ||
| In article | |||
| [18] | Takagi T. and Sugeno M.,1985. Fuzzy identification of systems and its applications to modeling and control. IEEE.Transactions on systems, man, and cybernetics, SMC-15. 1, 116-132. | ||
| In article | CrossRef | ||
| [19] | Vapnik, V., 1995. The Nature of Statistical Learning Theory. New York. Springer. | ||
| In article | CrossRef | ||
| [20] | Vapnik, V. and A. Lerner, 1963. Pattern recognition using generalized portrait method. Automation and Remote Control. 24, 774-780. | ||
| In article | |||
| [21] | Vapnik, V. N. and A. Y. Chervonenkis, 1991. The necessary and sufficient conditions for consistency in the empirical risk minimization method. Pattern Recognition and Image Analysis 1 (3), 283-305. | ||
| In article | |||
| [22] | Verma, A.K. and Singh, T.N. 2009. A Neuro-Genetic approach for prediction of compressional wave velocity of rock and its sensitivity analysis. Int. J.of Earth Sci. and Engg., 2 (2), 81-94. | ||
| In article | |||
| [23] | Young, R.P., Hill, T.T., Bryan, I.R. and Middleton, R., 1985. Seismic spectroscopy in fracture characterization. Q. J. Eng. Geol., 18, 59-479. | ||
| In article | CrossRef | ||
| [24] | Yudborovsky I and Vilenskaya S M., 1962. Some results of study of the elastic properties of rocks of western central Asia; Akad Nauk Turkmen SSR Ser Fiz-Tekh Khim Geol Nauk. 3, 26-31. | ||
| In article | |||

 CiteULike
CiteULike Delicious
Delicious

