 OPEN ACCESS
OPEN ACCESS  PEER-REVIEWED
PEER-REVIEWED
A New Iris Detection Method based on Cascaded Neural Network
Faezeh Mohseni Moghadam1, Azadeh Ahmadi1, , Farshid Keynia2
, Farshid Keynia2
1Department of Computer Engineering, University of Science and Technology, Kerman,Iran
2Graduate University of Advanced Technology,Kerman,Iran
Abstract
Iris recognition is one of the most reliable and applicable methods for a person's identification. The most complex and important phase of recognition is iris segmentation of an input eye image that affects iris recognition successful rate significantly. Due to missed parameters in noisy images, main error occurs in the performance of classic localization. Artificial neural networks (ANN) are appropriate substitutes for classic methods because of their flexibility on noisy images. In this paper, we use feedforward neural network (FFNN) for the improvement of iris localization accuracy. We apply two methods in order to reduce neural network error: first, designing one neural network for each output neuron .Second, using cascaded feedforward neural network (CFFNN). Then, we examine proposed methods on different datasets which cause remarkable reduction of localization error.
At a glance: Figures
Keywords: biometric, Iris localization, feedforward neural network, cascaded neural network, daugman's method,neural network designing
Journal of Computer Sciences and Applications, 2013 1 (5),
pp 80-84.
DOI: 10.12691/jcsa-1-5-1
Received December 30, 2012; Revised June 17, 2013; Accepted June 18, 2013
Copyright © 2013 Science and Education Publishing. All Rights Reserved.Cite this article:
- Moghadam, Faezeh Mohseni, Azadeh Ahmadi, and Farshid Keynia. "A New Iris Detection Method based on Cascaded Neural Network." Journal of Computer Sciences and Applications 1.5 (2013): 80-84.
- Moghadam, F. M. , Ahmadi, A. , & Keynia, F. (2013). A New Iris Detection Method based on Cascaded Neural Network. Journal of Computer Sciences and Applications, 1(5), 80-84.
- Moghadam, Faezeh Mohseni, Azadeh Ahmadi, and Farshid Keynia. "A New Iris Detection Method based on Cascaded Neural Network." Journal of Computer Sciences and Applications 1, no. 5 (2013): 80-84.
| Import into BibTeX | Import into EndNote | Import into RefMan | Import into RefWorks |
1. Introduction
Nowadays, considering the fact that, the protection of security information of countries, organizations and even the secret information of people having the highest degree of importance, an extreme need to create powerful ,exact and immune identification system is felt .Among the person’s biometric features, iris due to its texture, complexity and proved stability is applied as a suitable appropriate the person method for the person identification[Expert Systems With Applications 38,5940-5946,2011.">1, IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol.31, N0.9, September 2009.">8].
All of the iris recognition systems in the world which are based on Daugman’s algorithm have acceptable recognition rate. In addition, they contain problems, such as iris resizing by the affect of environment light variations, iris inconsistence in images and also they give the ability to represent the iris in fixed dimensions [2].This real time algorithm decodes visible random patterns in person’s iris in standard light conditions and distance. Then, people are identified by using a strong experiment of statistical analysis [3].The algorithm is commonly used in countries such as The United Arab Emirates ,England and the Netherlands, for controlling boundaries and migration tasks [3].
This study is based on Daugman’s algorithm. Identification process consists of four steps:Data acquisition, preprocessing, feature extraction and matching [4]. The preprocessing phase contains different steps. For example, pupil and iris boundaries , detection and removal of eyelashes, eyelids and normalization.
In 1994 Daugman [," IEEE Transaction CSV,Vol.14,N0.1,.21-30,2004.">9, IEEE Trans.Pattern Analysis and Machine Intelligence,Vol.15, No.11.1148-1161,1993.">10] presented the first phase-based method for iris recognition which phase information are independent from contrast and illumination of an image. In this method the pupil and iris boundaries are detected using integro-differential operator , given in Equation 1:
 | (1) |
I(x,y) is the image in spatial coordinates, r is the radius, (x₀,y₀) are center coordinates, Gσ(r) is Gaussian smoothing function of scale σ. At first, the maximum partial derivative of the contour integral of the image along the circular arc is calculated and the radius and center coordinates for pupil and iris are estimated .Eyelid boundaries are localized by parabolic arcs. Finally, the iris region of image is normalized to the polar form [18].
R.Wildes et al. [Machine visual Application, Vol.9,. 1-8,1996.">12, IEEE Proceedings, Vol.85, 1348-1363, 1997.">13, 14] iris recognition method is based on texture analysis .The pupil and the limbus are located by circular contours . The upper and lower eyelids are detected similarly with arcs instead of circles [11]. By using Hough transformation , edge points are detected which results in finding the particular values of circular contour parameters(x,y) and radius r.
Li Ma’s system [15] selects points of iris patterns with sharp intensity variations as the iris features. Then, the image is projected into horizontal and vertical directions. exact parameters of pupil and iris circles are estimated by applying canny edge detection and Hough transformation .The Cartesian coordinate of the iris is projected into a polar coordinate system. By employing Gabor filter, the frequency information for spatial patterns of an iris are acquired .Then, the feature extraction phase is started.
As described above, Wilde‘s and li Ma’s methods use Hough transformation. In Hough transformation algorithm [11], used an array, called accumulator to identify an existence of one line. Dimension of accumulator array is equal to unknown parameters of the problem .The line parameters are calculated for each point and it’s neighbourhood that can be considered as part of an edge. Then the location of saved parameters in the accumulator space is searched and by finding the highest values, the number of bin of the most probable lines is extracted and their geometric characteristic are read .The simplest way of finding them is applying different thresholds.
One weak point of Hough transformation is utilizing different thresholds for the edge detection. Different thresholds setting can cause variation edges, that impresses the results significantly [11]. Most of the other researchers working on iris localization only utilize gradient information of an image and their extraction rate is not high in practice [11].
In Fadi N.sibai et al. [1] study, at first preprocessing is done on jpg images and after removing the top and down part of image, the RGB values are retrieved by java software and stored in excel. Pupil and sclera regions of an image are eliminated. Iris data are prepared according to three partitions: horizontal, vertical and blocking.
The sum of RGB values of these partitions create the neural network’s input data. Finally , a feedforward neural network with one hidden layer is designed for recognition phase that has acceptable accuracy [1].
K.Saminathan et al. [5] developed previous algorithm and recognized pairs of iris with the same preprocessing and simple FFNN by employing error back propagation (EBP) training algorithm Without calculating the hamming distance. The neural network output for determining , weather the iris image is matched with real target or not, gives us yes/no answers which has proper accuracy.
Above described algorithms apply classic methods for iris localization which don’t have any intelligence, if it is possible to do iris segmentation with NN then more desirable performance will be achieved like using NN in matching phase gives favorable results.
In the paper of Rugggero Donida Labati et al. [4], an iterative method is presented for center and boundaries of iris detection. This algorithm starts with random initial pixels in input image .Then a series of local characteristics of the image from circular region of search space are extracted and are processed for variable patterns in iris boundaries. NN with parameters related to extracted boundaries is trained. By paying attention to calculated center, offsets in vertical and horizontal axis are estimated. Then the coordinates of starting points are updated with processed offsets .This algorithm iterates in fixed steps and based on the number of iterations, it’s results are refined. Also, the pupil and its boundaries are detected better. This method is applicable and has notable accuracy even when it is used on non-ideal or noisy images. When it starts from the points near to pupil or iris, it performs very well but when starts from other points related to the other regions of the image, the accuracy decreases. The main deficiency of this algorithm is its strong dependency of the initial start points, because it has random base [4].
In the other research [6], one neural network is trained based on Daugman’s method, which has minimum iris localization response time ,namely, detection speed and proper accuracy level .This localization algorithm suffers from the brightness of light in the pupil , that reduces the localization accuracy [6]. All of the existing iris localization algorithms can be implemented by using reformed neural networks such as SOM (self organized map), FF and CFF. One advantage of these methods is. One advantage of these methods is implementation of redundancy of feature space [7].Considering that NN in localization has good flexibility on noisy images while missed parameters cause large error in classic localization performance[6], therefore ,creating a NN is one reasonable superseded for iris localization and helps to performance increasing and accuracy of such systems.
This paper is organized as following: Our proposed method is explained in section two ,which discusses about data preprocessing, designing and improvement of neural network structure and the methods which are employed for NN's performance enhancement are described in the section three. In the last section the results of proposed method are presented and discussed.
2. Proposed Method
In our proposed approach which is based on Daugman's method [18], in the first step, preprocessing operation is done on the input images . Here ,we use CASIA _iris_ interval (v3) database images .In the second step, prepared data presented to the NN as an input, and the iris segmentation is learned in the internal procedure of the NN, finally according to the iris polar form ,the NN output will be obtained .In the next steps of the algorithm ,the structure and performance of the NN are enhanced respectively. The activities done on the input image are shown in Figure 1.


 PowerPoint Slide
PowerPoint Slide Larger image(png format)
Larger image(png format)


In order to better the training phase ,it is necessary to preprocess on data .At first ,the scale of input-output must be assimilated .Toward preparing a relevant mapping between the input and the output, it is offered to vector the matrix of input images. Since the size of input images are 320*280, the number of input layer neurons will be numerous which subsequently leads to increase the time and memory of training dramatically. Hence, for deleting the similar data from input matrix, the correlation method is utilized.
The most famous evaluation criterion of dependency between two quantities is called Pearson's correlation [16] .The population correlation coefficient ρx,y between two random variables X and Y with expected values µx and µy and standard deviations ơx and ơy is given in Equation (2).
 | (1) |
Where E is the expected value operator, cov means covariance and, corr is widely used as an alternative notation for Person's correlation. If the variables are quite independence, the corr output is zero. If there is fully positive linear relation(correlation),the output is +1 and if there is fully negative linear relation(anti-correlation),the output is -1. The results between -1,+1 indicate the degree of linear dependency between variables.
In order to access the most appropriate number of input and output neurons, different threshold values for correlation are examined. For the reason that eye information have great volume, we use row partitioning to remove similar data. We apply correlation on the results of improved combined partitions. According to different thresholds, three groups of datasets are created .The input matrix is 89600*100 which a correlation with threshold value of 95% on every row partitioning is exerted .The target matrix is 4800*100.The final results of correlation on input partitions and target matrix for preparing datasets are shown in Table 1.

 PowerPoint Slide
PowerPoint Slide Larger image(png format)
Larger image(png format) View current table in a new window
View current table in a new windowOne of the most common method for smart building is applying NN. Several existing neural networks are radial basis function(RBF),multi-layer perceptron(MLP) and feedforward neural network(FFNN) [17]. Using FFNN widely in data processing , speech recognition , image processing and forecasting tasks gets a long with success that causes these networks known as the most applicable and well-known networks .With FF networks having one hidden layer and sufficient neurons, it is possible to perform every input-output mapping.
Layer structure of this network is consists of one or more processing units which is called neuron .The neurons of every layer are connected to one or more neurons in next layer and there isn’t any connection between neurons of each layer with themselves. These connections with parameters of real value are named weight .The number of input, hidden and output neurons of one NN must be harmonized .Also the number of training samples for training NN is important, because if they are chosen less or more, the NN has incomplete training or become overtrained ,so we use 90 images as training samples and 25 images for testing.
2.3. Training MethodTraining a neural network model means selecting one model from the set of allowed models that minimizes the cost criterion. There are numerous algorithms available for training neural network models; most of them can be viewed as a straightforward application of optimization theory and statistical estimation.
Most of the algorithms used in training artificial neural networks employ some form of gradient descent. This is done by simply taking the derivative of the cost function with respect to the network parameters and then changing those parameters in a gradient-related direction.
Usual learning process are denominated forwardpropagation. If there is an error between the actual output and the output estimated by the NN , the learning process changes to a method named, back propagation , which feedbacks and adjusts the weight values for each layer again. In order to weights adjustment for minimizing the error, this algorithm uses the gradient of performance function. The structure of feed forward neural network with backpropagation training algorithm is shown in Figure 2.

 PowerPoint Slide
PowerPoint Slide Larger image(png format)
Larger image(png format)
Activation function for each neuron uses sigmoid continuous function that is described in Equation 3:
 | (3) |
we use 90 images as training samples and 25 images for testing.
2.4. Designing Neural NetworkMany researches illustrate that the accuracy of obtained solutions from neural network strongly depends on the size of this neural network .The size of neural network affects on the complexity, the training time and, the most important one, the possibility of neural network generalization .The number of input and output neurons can be determined based on the problem dimensions .A neural network with two hidden layers can estimate any arbitrary non-linear function and, generates any complex region of decision for classification problems .But it is possible that ,more hidden layers lead to more exact and rapid answers in practice.
Different sizes of neural network must be examined totally, because via try and error the fit size of neural network will be obtained .The big neural networks need many training samples to achieve good performance. Whereas the small neural networks which can learn the desired mapping owing to consume less memory and less computational time and easier implementation ,are better theoretically and practically [19]. Also, it is so important that in the testing phase we get a quick answer .we represent the results of training three datasets with the simple feedforward neural network ,the error back propagation training algorithm and, one hidden layer with ten neurons .Here, for evaluating the performance of this NN ,the mean absolute percentage error (mape) is used .This error formula is shown in an equation 4,which O is the actual target and F is the NN output.
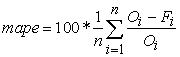 | (4) |
A feedforward neural network with error back propagation training algorithm ,tansig transfer function and ,one hidden layer with ten neurons is applied .The results of this network with three datasets are shown in the Table 2.

 PowerPoint Slide
PowerPoint Slide Larger image(png format)
Larger image(png format) View current table in a new window
View current table in a new window2.5.1. Multilayer Feedforward Neural Network
As explain above ,it is possible that using more than one hidden layer causes better estimation. After many examinations of datasets on neural networks with multi hidden layers and different number of hidden layer neurons ,we understand that in iris localization ,neural networks with two hidden layers perform better than neural networks with one hidden layer, and the best error average occurs even in more layers.
2.5.2. Transfer Function
In order to access the properties that simplify or improve the neural network containing neurons ,transfer function for each neuron is utilized .The bipolar function of sigmoid is called tansig which is in the range of [-1,1].When the speed is more important than the exact shape of the transfer function ,this function is a suitable tradeoff for neural network .The logsig function receives the infinite positive and negative inputs and converts the output into the range of [0,1]. This function is commonly used in multilayer feedforward with error back propagation training algorithm.
After comparison of neural network performance with two transfer functions , logsig and tansig ,we get the attractive results which indicate that though the logsig function decreases the speed of neural network a little ,but decreases the training error of the neural network a lot . The results of using multilayer feedforward neural network and logsig transfer function are shown in Table 3.

 PowerPoint Slide
PowerPoint Slide Larger image(png format)
Larger image(png format) View current table in a new window
View current table in a new window3. Enhancment of Neural Network Performance
3.1. One Neural Network for Each Output Neuron(Multinet)The number of neurons in output layer is one of the system's freedom degree .It is better that the neurons of the output layer don't exceed from one neuron and whereas the number of output layer neurons are equal to the number of outputs [19] ,so it is better to get the outputs one by one , videlicet every neural network generate one output neuron to enhance the accuracy. Table 4 presented the results of this approach.

 PowerPoint Slide
PowerPoint Slide Larger image(png format)
Larger image(png format) View current table in a new window
View current table in a new windowThe main problem of using a NN is ,it's initial weights and bias ,which are selected randomly that cause the NN substantial error .For reducing this error ,a method that cascades the NN can be applied .In this solution the weights and bias of the trained NN are transfered to the second one, as the initial weights and bias .If it can be feasible that among the trained NNs, acquired weights and bias from the NN that has the best result( the minimum error), can be transfered to the second one by a controlled way , the NN output gives more better results whereas , the second NN is learned with suitable trained weights and bias instead of initial random ones. In Figure 3, the structure of cascaded neural network is illustrated and in Table 5, the results of using CFFNN are presented.

 PowerPoint Slide
PowerPoint Slide Larger image(png format)
Larger image(png format)
) PowerPoint Slide
PowerPoint Slide Larger image(png format)
Larger image(png format) View current table in a new window
View current table in a new window4. Conclusion
The aim of this paper is presenting an intelligent approach with an acceptable error and time for iris localization. After finding proper structure of NN for this application, the proposed method is improved by using One neural network for each output neuron (multinet) and cascaded neural network. It is seen that the multinet method can boost accuracy somedeal , but cascading can improve it more noticeably and aggress us to our purpose .According to the Table 3, and Table 5 for dataset(b) by using 6 layer FFNN, the minimum error is 1.5237, whereas, minimum error in the cascaded improved NN, changes to 0.8935. During different experiences with cascaded NN ,the iris is localized by good estimation .The best result of NN performance is the minimum error 0.8935 which indicates that the estimation of iris location is done very well. Also the appropriate training time 52 seconds and testing time 0.0532 seconds is achieved in this chosen neural network. so we attain the more powerful system in iris recognition phase .If it is possible to generalize these networks in the way that the weights and bias can be controlled, our network will take place in the best situation.
References
| [1] | Fadi N.Sibai, Hafsa I.Hosani, Raja M.Naqbi, Salima Dhanhani, Shaikha Shehhi ,"Iris Recognition Using Artificial Neural Networks," Expert Systems With Applications 38,5940-5946,2011. | ||
 In article In article | CrossRef | ||
| [2] | http://en.wikipedia.org/wiki/Iris_Recognition. | ||
| In article | |||
| [3] | ]http://www.wikipedia.org/wiki/John_Daugman. | ||
| In article | |||
| [4] | Ruggero Donida Labati ,Vincenzo Piuri Fellow, Fabio Scotti,"Neural-based Iterative Approach for Iris Detection in Iris Recognition systems," Proceedings of the 2009 IEEE Symposium on Computational Intelligence in Security and Defense Applications (CISDA ). | ||
| In article | CrossRef | ||
| [5] | K.Saminathan, M.Chithra Devi,T.Chakravarthy "Pair of Iris Recognition for Personal Identification Using Artificial Neural Network," IJCSI International Journal of Computer Science Issues, Vol.9, Issue 1, No.3, January 2012. | ||
| In article | |||
| [6] | Poornima.S,C.Rajavelu, Dr.S.Subramanian," Comparison and Neural Network Approach for Iris Localization," Procedia Computer Science 2,127-132, 2010. | ||
| In article | CrossRef | ||
| [7] | Shivani Godara, Dr.Rajeev Gupta" Comparison of Different Neural Networks for Iris Recognition :A Review," Network and Complex Systems, Vol.2,N0.4,2012. | ||
| In article | |||
| [8] | Zhaofeng He, Tieniu Tan,Fellow, Zhenan Sun, Xianchao," Toward Accurate and Fast Iris Segmentation for Iris Biometrics," IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol.31, N0.9, September 2009. | ||
| In article | |||
| [9] | Daugman J," How Iris Recognition Works," IEEE Transaction CSV,Vol.14,N0.1,.21-30,2004. | ||
| In article | |||
| [10] | J.Daugman," High Confidence Visual Recognition by a Test of Statistical Independence," IEEE Trans.Pattern Analysis and Machine Intelligence,Vol.15, No.11.1148-1161,1993. | ||
| In article | |||
| [11] | Abdul Basit," Iris Localization Using Grayscale Texture Analysis And Recognition Using Bit Planes", 2009, 16-26. | ||
| In article | |||
| [12] | R.Wildes, J.Asmuth, G.Green, S.Hsu,R.Kolczynski, J.Matey and S.McBride," A Machine Vision System for Iris Recognition," Machine visual Application, Vol.9,. 1-8,1996. | ||
| In article | |||
| [13] | R.Wildes, " Iris Recognition: An Emerging Biometric Technology, "IEEE Proceedings, Vol.85, 1348-1363, 1997. | ||
| In article | |||
| [14] | R.Wildes,”A System For Automated Iris Recognition,” Proceeding of 2nd IEEE Workshop on Applications of Computer Vision, 121-128, 1994. | ||
| In article | |||
| [15] | Li Ma, Tieniu Tan, Yunhong Wang, Dexin Zhang," Personal Identification based on Iris Texture Analysis," IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol.25, No.12, 1519-1533,2003. | ||
| In article | |||
| [16] | ]www.wikipedia.org/wiki/Correlation_and_dependence. | ||
| In article | |||
| [17] | Jain.A.,Ross.A.,& Prabhakar.S," An Introduction to Biometric Recognition," IEEE Transactions on Circuits and System for Video Technology. Special Issue on Image and Video – Based Biometrics,2007. | ||
| In article | |||
| [18] | Libor Masek, “Re1cognition of Human Iris Patterns for Biometric Identification”, School of Computer Science and Sof t Engineering, The University of Western Australia, 2003. | ||
| In article | |||
| [19] | George Bebis, Michael Georgiopoulos" Optimal Feedforward Neural Network Architectures," IEEE Potential separtment of Electrical & Computer Engineering University of Central Florida, Orlando, FL 32816 USA, 2011, 27-3. | ||
| In article | |||

 CiteULike
CiteULike Delicious
Delicious

